2022 年底 ChatGPT 出来的时候,用过的人似乎都有一种感觉,这家伙不是 Siri,也不是小爱同学,它看起来就像《终结者》里的天网,或者《生化危机》里的红皇后那样,像是真的人工智能。它听得懂人话,它能理解你的意思,你居然可以用大白话和它聊天。
后来这些年,我越往里摸,越觉得它的核心秘密简单到甚至有点让人失望。
它就是在猜下一个字。
没有别的。
给它一段开头,比如“今天天气真”,它内部会先算出一个概率分布。说得再直白一点,它会看着前面这几个字,判断下一步最可能接什么。
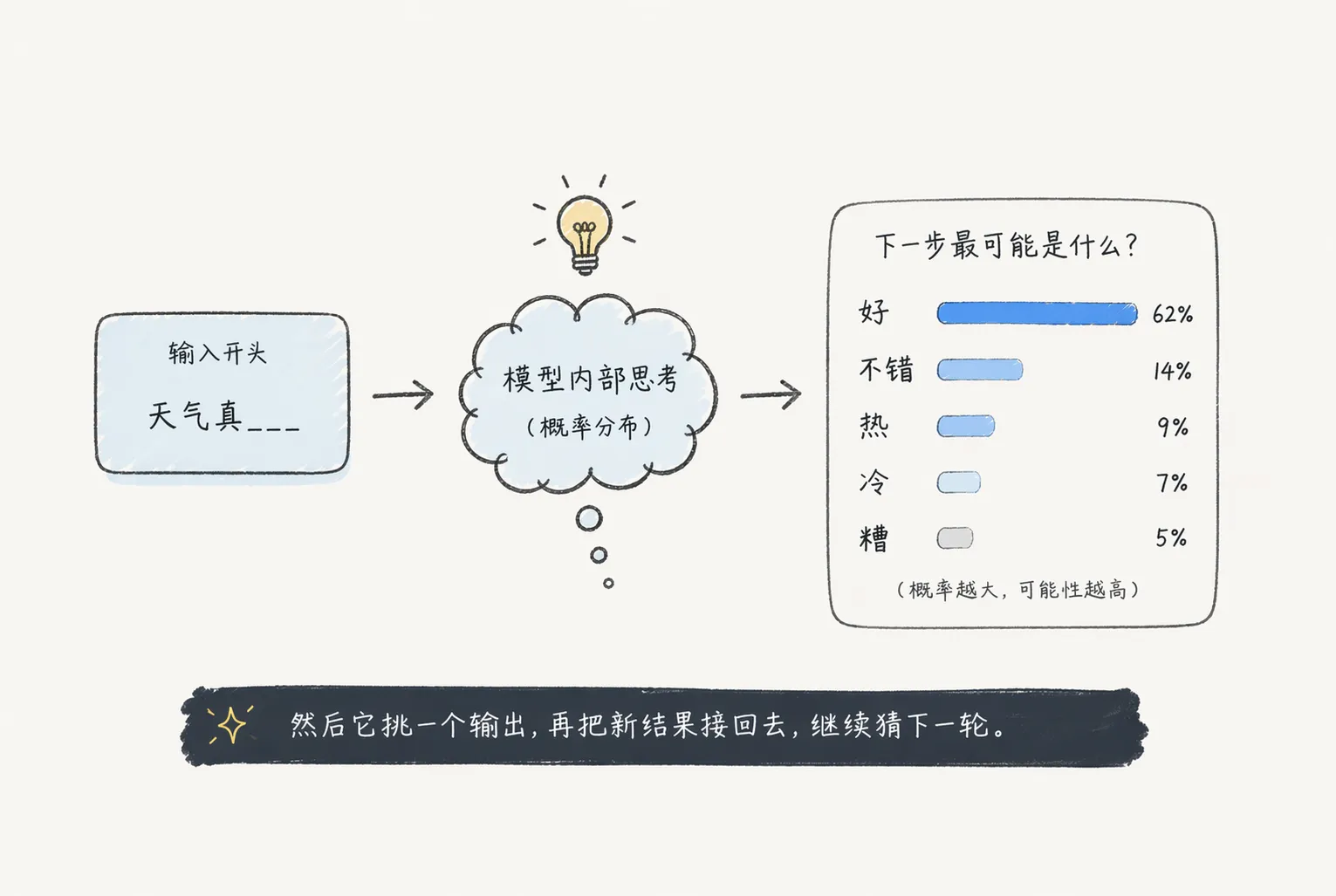
图 1:LLM 的底层动作,说到底就是看着当前输入,继续往后滚最可能的 token。
然后它挑一个输出。通常是取概率最高的,或者按概率采样。下一轮,它再把“今天天气真好”当成新的输入,继续猜。
技术上更准确一点,它猜的其实不是“字”,而是 token。token 可能是一个字、半个词、一个词,也可能是标点。你跟它聊天时看到的所有文字,不管多流畅、多聪明、多像有洞察,底层都是这样一个 token 一个 token 滚出来的。
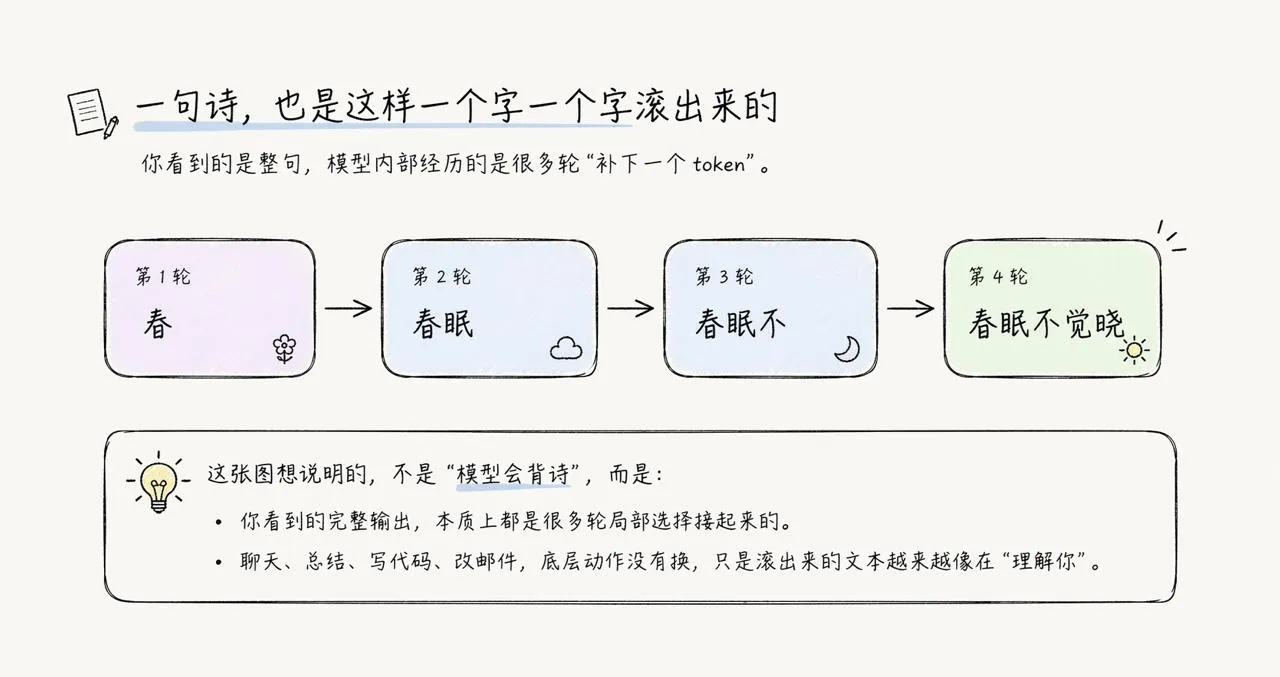
图 2:你看到的是一句完整输出,模型内部经历的是很多轮局部预测。
这里顺手再补另一个高频词,prompt。你现在发给模型的那段输入,不管是一个问题、一串要求、一段上下文,还是一整份文档,通常都可以叫 prompt。模型做的事,本质上就是看着当前 prompt 里的 token,继续往后滚最可能的 token。
这也是为什么我现在特别不愿意一上来就把 LLM 讲得太神。它当然很强,但它不是先“想通了”再回答你。它是沿着前文,继续把最像答案的东西滚出来。
Transformer 架构
2017 年 6 月,Google Brain 的 8 个研究员挂出一篇论文,标题叫《Attention Is All You Need》。这篇论文就是 Transformer 架构的核心理论。
那当时 AI 圈什么反应?
基本没反应。
那会儿所有人都在卷 RNN 和 LSTM。顶会论文的 baseline,几乎都是“在 RNN 上再加点什么”。Transformer 听起来更像又一个奇技淫巧,很多人翻一翻就滑过去了。
直到一年多以后,这个架构才把整个 NLP 领域的地基重浇了一遍。
2017 年之前,大家卡在哪。 那时候处理语言的主流是 RNN 和它的变种 LSTM。思路和人读书有点像,从左到右一个字一个字读进去,用一段“记忆”继续往后传。听起来挺合理,但有两个要命的问题。
第一是训练慢。必须一个字一个字处理,前一个没算完,后一个不能开始。GPU 性能再强,也被这个串行流程锁死了。那会儿训练一个像样的语言模型,动不动就是几周。
第二是记不住长序列。读到第 100 个字时,第 1 个字的信息已经被稀释得差不多了。就像你读一本书读到第 10 章,前面很多细节已经糊了。
2014 年 Bahdanau 那批人第一次把 attention 机制引进神经机器翻译,让解码器能“回头看”编码器的所有输出。效果很好,但本质上还是挂在 RNN 身上用。那时候的 attention,还是配菜。
8 个人的狠活。 这 8 个人干了一件当时看起来很疯的事,把 RNN 彻底扔掉,只留 attention。 论文标题本身就是挑衅,attention 就够了,别的都不要。
它解决了什么?
- 并行化:每个 token 可以同时看别的 token,不用排队,GPU 终于能满血跑
- 远程依赖:不管两个词隔多远,中间都可以直接建立 attention,不再像 RNN 那样越传越淡
但论文发表时,他们的实验场景其实很窄,主要还是英语翻德语。效果比当时的 SOTA 好了一点,但远没到“所有人起立鼓掌”的程度。
被冷落的那一年多。 论文发出去后,大概一年多都没掀起什么大浪。真正让人坐起来的是 2018 年。6 月 OpenAI 发了 GPT-1,10 月 Google 推了 BERT。BERT 出来之后,几乎把整个 NLP 圈重新洗了一遍,很多任务的 SOTA 记录都被一口气刷掉。
但真正把“Transformer 这条路没有悬念了”这件事钉死的,是 2020 年 6 月的 GPT-3,1750 亿参数。
它已经不是“某几个任务表现不错”这么简单了。它开始表现出一种很新的感觉,你不用再给每个任务单独训练一套模型,你只要写一段自然语言描述,也就是一个 prompt,它就能大致知道你想让它干什么。
从 2017 年 6 月 Transformer 论文发出来,到 2020 年 GPT-3 亮相,整整三年。
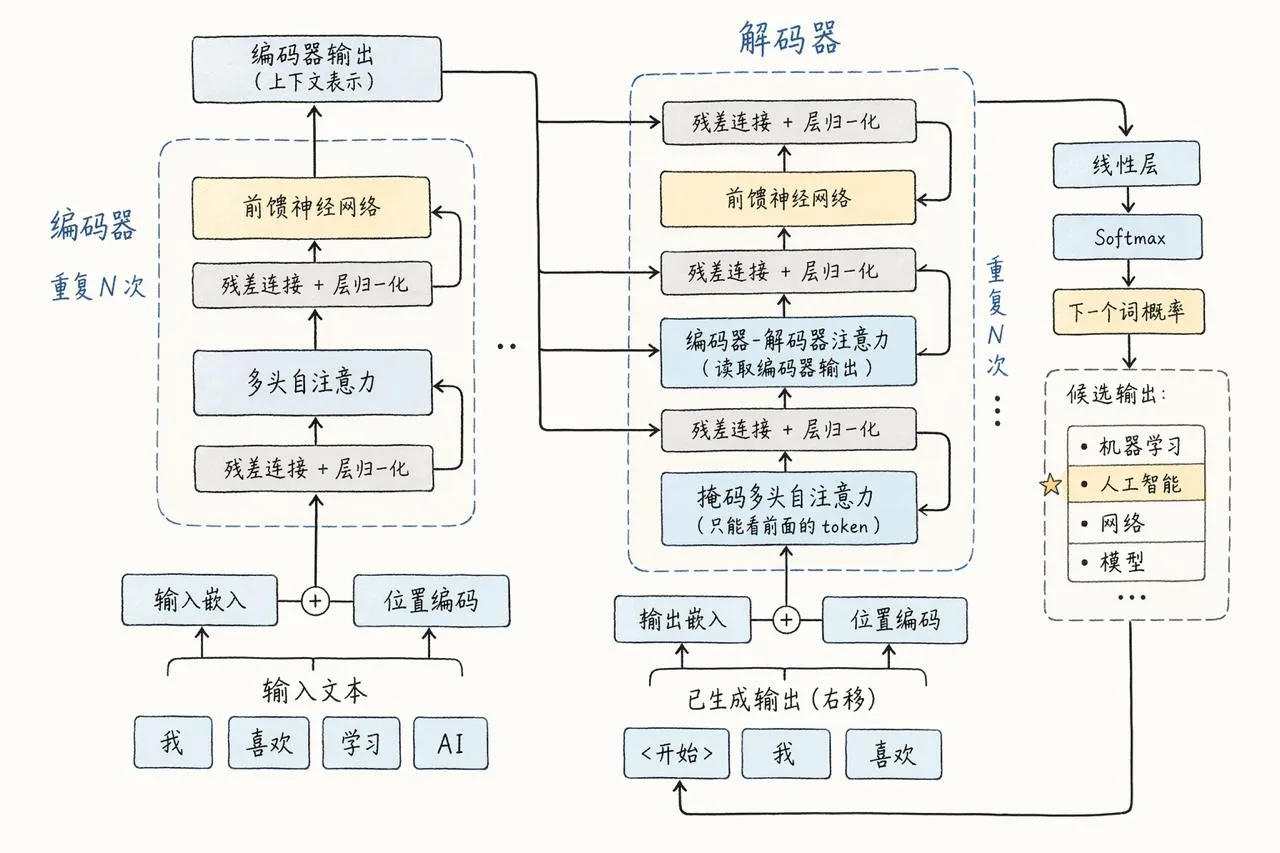
图 3:Transformer 架构真正值钱的地方,不是图长什么样,而是它终于把“能处理全局关系”和“能大规模并行训练”绑到了一起。
LLM 训练过程
聊到这里,问题就顺着来了。既然它底层就是在猜下一个 token,那它是怎么从“会续写”一路长成今天这个样子的?
大体上可以拆成三步。
第一步,先把它喂大。 最前面那一步叫预训练。做法其实很朴素,就是把海量网页、书、论文、代码、论坛文本一股脑喂进去,让模型反复做同一件事:预测下一个 token。
这一步不教它“什么叫有礼貌”,也不教它“怎么像客服一样回答”。它只是让模型在海量文本里把语言模式、事实碎片、表达习惯和常见结构一点点压进参数里。
所以预训练之后的模型,更像一个很会续写的人。你给它一个开头,或者给它一段 prompt,它都能顺着往下走。但它不一定真的知道你想要什么格式,也不一定特别愿意按你的要求来。
第二步,再把它训成“会按要求回答”。 这一步通常叫 instruction tuning,或者监督微调。说白了,就是拿一批“问题 → 理想回答”的样本继续喂给模型,让它慢慢学会一件事:用户这样写 prompt,通常希望收到怎样一种回答。
这一步特别关键。因为用户想要的,从来不是一个单纯会续写的模型,而是一个能听懂任务要求、按要求组织输出的系统。也正是从这里开始,prompt 才真正像一个任务接口,而不是随便丢给模型的一段文字开头。
第三步,再用人类反馈把它往“助手感”上拽。 后面还有一层就是大家常提的 RLHF。别被这个缩写吓住,它最核心的想法其实不复杂:让人去比较多个回答,选出哪个更像人真正想要的,然后再继续把这种偏好压回模型里。
所以今天这种聊天体验,不是只靠参数越堆越大自动长出来的。它还靠后面这层对齐过程,把模型从“会生成文字”继续往“更像在和人说话”那边推。
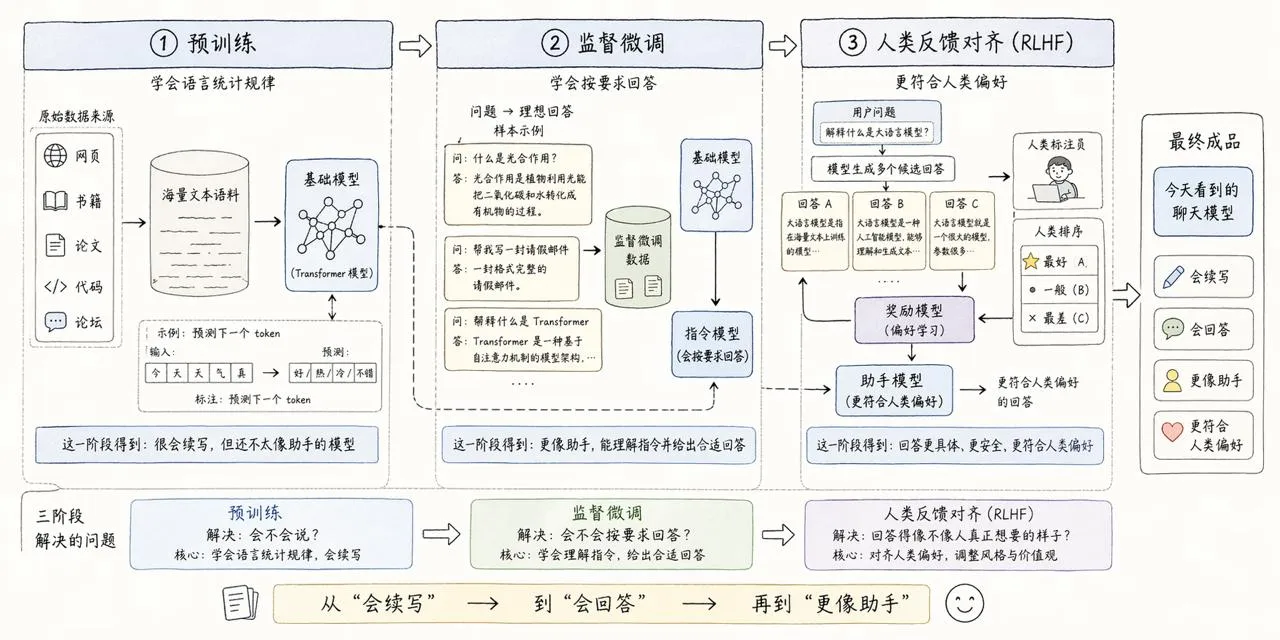
图 4:预训练解决“会不会说”,后面两步主要在解决“能不能更像人在跟你说话”。
这里有个很有意思的反差。OpenAI 当年在 InstructGPT 论文里就发现,1.3B 的 InstructGPT 输出,标注者会明显更喜欢,而不是原始 175B GPT-3 的输出。这说明一件事,好用,不只是更大。很多时候,还得更会听话。
Context Window
再往后,几乎所有人都会碰到另一个高频词,Context Window。
这东西经常被讲成“模型的记忆力”,但我觉得这个说法很容易把人带沟里。它更像模型眼前这一张临时工作台,不像一个会自动长期积累的脑子。
你这一轮喂进去的 prompt、系统提示、对话历史、文档片段,能不能一起放在桌上,取决于这个窗口有多大。换句话说,Context Window 本质上是在规定,这一次 prompt 最多能带多少 token 上桌。
但问题也正出在这里。很多人一看到“100K”“200K”“1M”这样的窗口数字,就会下意识觉得,模型是不是已经什么都记得住了。
不是。
窗口变大,只是桌子变大。桌子变大,不代表人就自动更会判断。材料一多,检索、聚焦、回忆都会开始掉。这也是为什么长上下文模型虽然厉害,但实际用起来还是经常需要你帮它整理材料、裁切重点、明确 prompt。
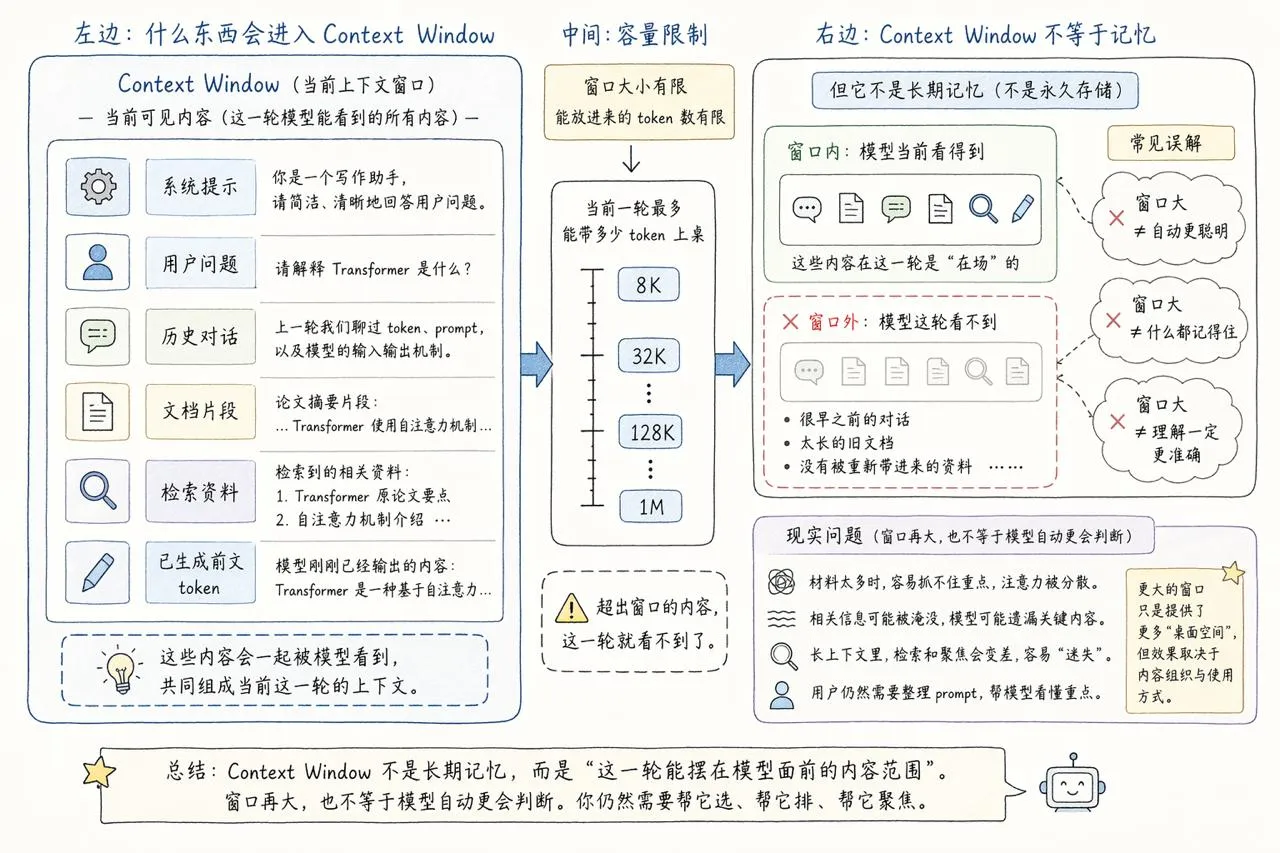
图 5:更长的 Context Window 更像更大的草稿纸,不像额外长出了一套永久记忆。
所以如果你要用一句最不容易误导的话来理解它,我现在会这么说:
Context Window 不是记忆力本身,而是这一次交互里,模型眼前能摊开多少 token、多少 prompt 材料。
如果现在让我用一句话压缩 LLM,我会说,它不是突然觉醒的数字生命,而是一套建立在 Transformer 架构之上、通过海量文本预训练出来的下一个 token 预测系统。
只是这个系统后来越做越大,训练流程也越补越多,于是它看起来越来越像在“理解你”。
这也是我现在最想保留的判断。它当然已经很强了,强到足够改变很多人的工作方式。但你越早接受它底层其实还是在滚 token,这东西反而越好用。因为你会知道,什么时候该用它,什么时候不该把它想得太神。