这篇文章默认你已经用过 ChatGPT、Claude、DeepSeek 这类聊天工具,但不需要你有编程或数学基础。
你跟 ChatGPT 聊天时,背后真正干活的,就是一个大语言模型。
如果按教材写,它的定义大概是这样:
大语言模型(Large Language Model,LLM)是基于海量数据预训练的深度学习模型,利用拥有数亿至数万亿参数的神经网络(通常为 Transformer,也就是“转换器”架构)来理解和生成人类语言。它们通过自监督学习,根据前文预测下一个标记(token),具备文本生成、翻译、总结和代码编写等多种自然语言处理能力。
这段定义很标准,也很容易看完就忘。先不用急着背,真正要抓住的是它背后的动作。
学习 LLM 的时候,最容易卡住的是名词之间的关系:
- LLM
- GPT
- ChatGPT
- Transformer
- token
- prompt
- 上下文窗口
- RAG
- 工具调用
这里先垫一下:prompt 就是你输入给模型看的内容;上下文窗口就是它这次最多能看多少内容;RAG 可以先理解成“先查资料,再让模型回答”。
每个词单独看都能查到定义,放在一起就像一团线。
这篇就是来干一件事的:把这团线拆开。
它不会假装把所有数学细节都讲完,但会把后面反复遇到的概念先摆成一张地图。知道每个词放在哪一层,之后再看 ChatGPT、Claude、Gemini、DeepSeek,就不容易被名字绕进去。
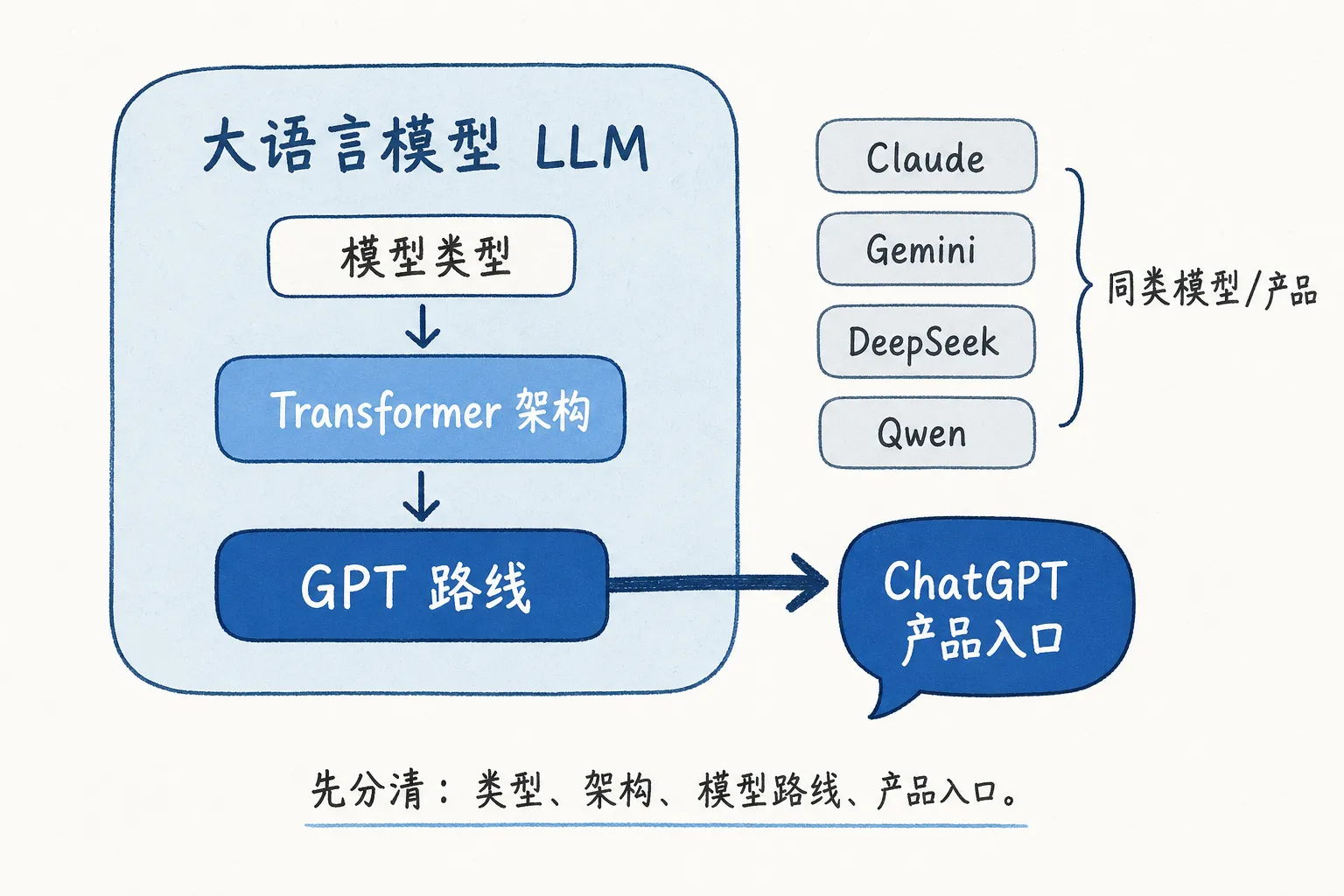
01|名词关系
先把最容易混的几个词放准。
LLM 是一个大框,指一类能处理和生成语言的大模型。GPT(Generative Pre-trained Transformer,生成式预训练 Transformer)、Claude、Gemini、Qwen、DeepSeek,都可以放进这个框里。
Transformer 是今天主流 LLM 常用的架构。它是一种处理序列数据的神经网络结构。2017 年 Google 那篇《Attention Is All You Need》把这套结构推到台前,后面的 GPT、BERT(Bidirectional Encoder Representations from Transformers,双向 Transformer 编码表示)以及很多聊天模型都沿着这条路往下走。
GPT 是一条具体的模型路线。这个名字已经把核心说出来了:生成式、预训练、Transformer。GPT-3、GPT-4 都是这条路线上的模型。
ChatGPT 则是 OpenAI 在 2022 年 11 月推出的聊天产品。普通人真正感到震动的点在这里:模型能力第一次被放进一个网页对话框里,可以直接聊天、改代码、写邮件、承认错误。
这几个词的层级大概是:LLM 是模型类型,Transformer 是架构,GPT 是模型路线,ChatGPT 是产品入口。
02|生成原理
LLM 最底层的动作,听起来有点朴素:
它在预测下一个 token。
为了方便理解,可以先粗略说成“猜下一个字”。token 可以先理解成模型处理文本时的一小块单位,下一节会展开。
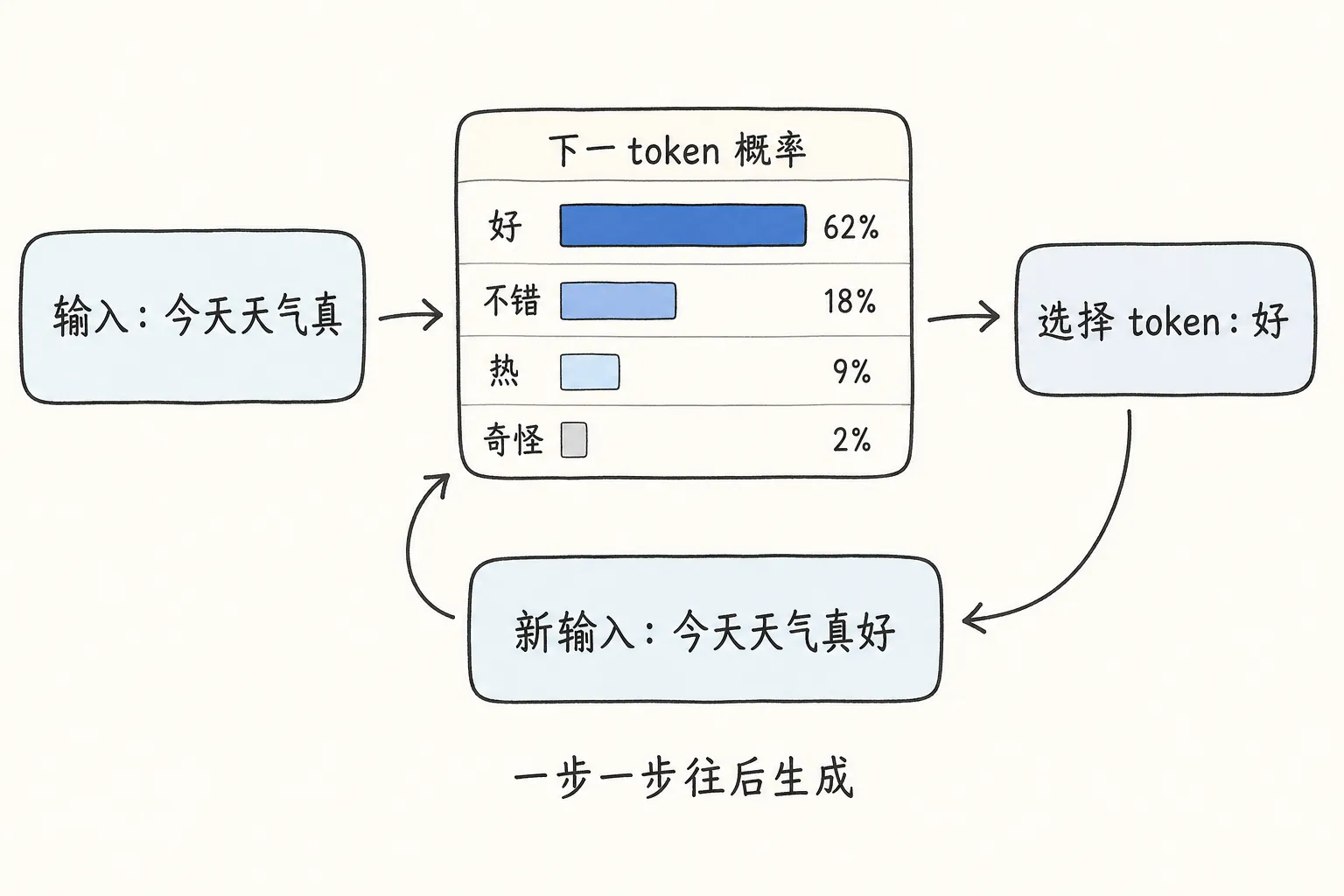
比如输入:
今天天气真
模型内部会算出一个概率分布。下一个 token 可能是:
- “好”——概率最高
- “不错”——概率次高
- “热”——也有可能
- “奇怪”——概率低一点
模型选出一个 token,比如“好”。于是当前文本变成:
今天天气真好
它再基于这段新文本继续预测下一个 token。这样一步一步滚下去,慢慢变成一句完整回答。
你看到的是一整段话,模型实际做的是一连串选择。
同一个问题有时会得到不同回答,原因就在这里:模型没有从固定答案库里取结果,而是在当前上下文里不断生成最可能接下去的内容。
这里有一个容易误解的地方。
说它“预测下一个 token”,不等于说它很笨。一个足够大的模型,在足够多的数据上训练过之后,预测下一个 token 这件事会被逼着学到很多东西:语法、事实、代码格式、推理模式、问答习惯、写作风格。
它没有像人一样先在脑子里想好一整段意思,再把意思翻译成文字。它更像是在一个极大的语言空间里,根据上下文一步步往前走。
这话听着有点不爽,但它能解释很多现象:
- 为什么它能写得很流畅
- 为什么它会一本正经地编错事实
- 为什么 prompt 改几个字,输出就可能变掉
- 为什么长对话会越来越贵
LLM 的很多能力和很多毛病,都能从“预测下一个 token”这件事往外推。
03|Token 单位
token 这块确实要先纠正一个常见误解:它不是字,也不是完整的词。
它是分词器切出来的最小处理单位。英文里,一个 token 可能是一个词,也可能是一个词的一部分,还经常带着前面的空格。中文里,一个 token 可能是一个字,也可能是一个子词。
比如英文句子:
I don’t like waiting
在 GPT 类模型里可能被切成:
Idon'tlikewaiting
这里的空格也被算进 token 里。
中文会更复杂一点。常见字可能单独成 token,不常见组合可能被拆得更碎。你不用背分词算法,但要知道一件事:
模型不是直接按“字数”或“词数”工作,而是按 token 工作。
最直接的影响是费用。如果你只是打开 ChatGPT 网页聊天,通常不会直接看到 token 账单;但开发者在自己的程序里调用模型时,一般会通过 API(Application Programming Interface,应用程序接口)来用模型,费用就按 token 算:发进去 2000 个 input tokens,模型吐出来 1000 个 output tokens,账单按这 3000 个 token 算。
输入越长,模型要处理的 token 越多,响应通常也越慢。上下文窗口同样按 token 算。你说“我塞了一整篇文章进去”,模型看到的其实是一串 token。
后面讲 prompt、context window、temperature,都会回到这个单位上。
04|训练过程
如果 LLM 只是预测下一个 token,为什么它没有一直写小说,反而能回答问题?
答案在训练过程里。
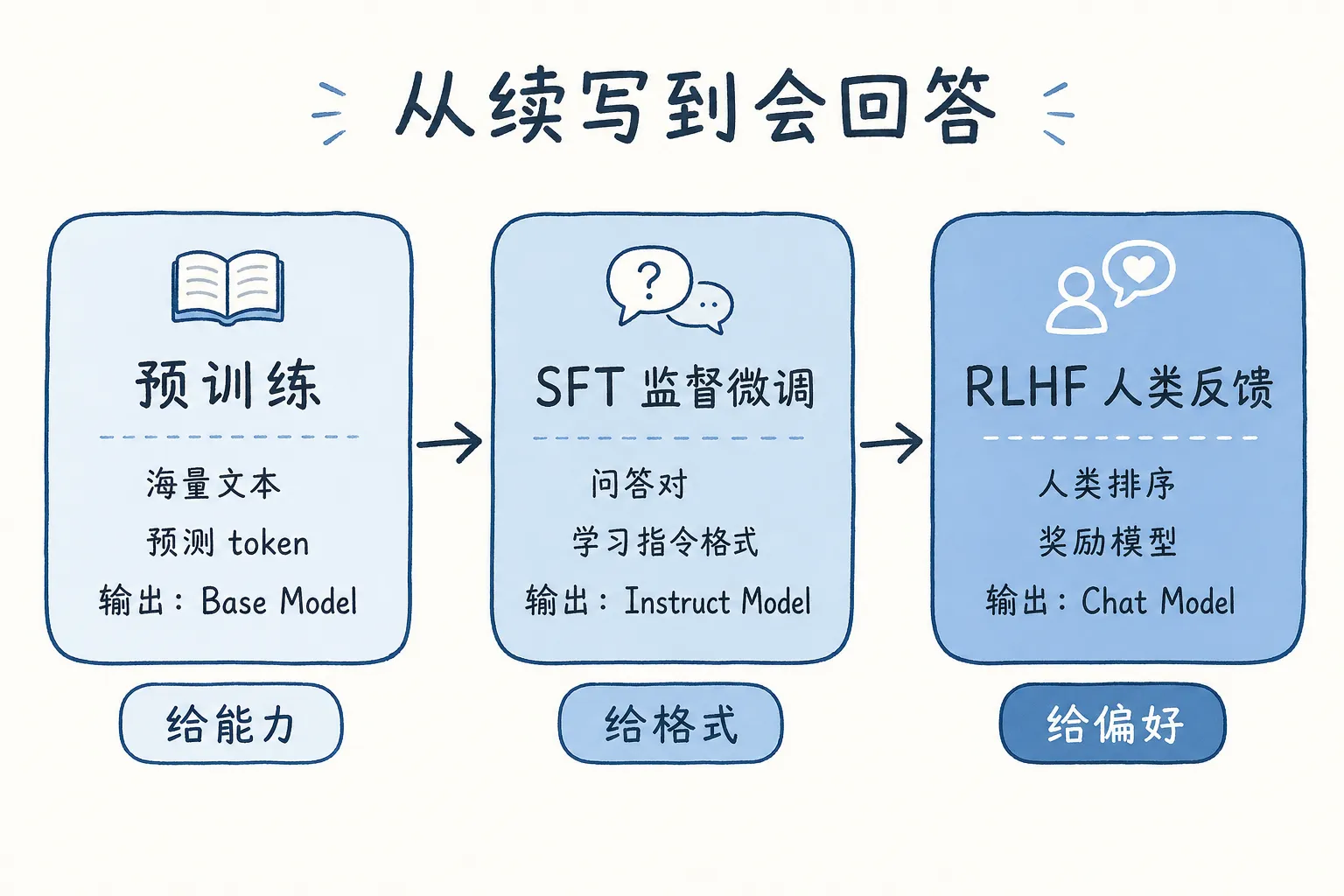
一个能聊天的模型,通常不是只训练一次就结束。更像是经历几轮不同目标的训练。
预训练:先学会续写
预训练是最大的一步。
做法可以粗略理解成:把大量文本喂给模型,让它不断做预测下一个 token 的练习。
比如训练文本里有一句:
北京是中国的首都。
模型看到“北京是中国的”,它要预测后面更可能接“首都”。猜对了,参数往这个方向调;猜错了,也根据误差调参数。
这个过程不需要人工给每句话打标签。文本本身就能提供训练信号:前文是输入,后文就是答案。
预训练结束后,会得到一个 base model。它很会续写,但不一定会按你的要求回答。
你问它:
什么是光合作用?
它可能续出:
什么是光合作用?这是一道常见考试题……
它没有故意捣乱。预训练阶段学到的主要动作是“接着写”,还没学会“当一个助手回答”。
SFT:把续写调成问答
SFT 是 Supervised Fine-Tuning,监督微调。
这一步会准备一批人工写好的问答对。比如:
- 用户问:什么是光合作用?
- 理想回答:光合作用是植物利用光能,把二氧化碳和水转化为有机物,并释放氧气的过程。
模型继续在这些数据上训练,开始学会一种新格式:别人问问题,我就给出像样的回答。
这一步不一定需要预训练那种海量数据,但对产品体验很有影响。没有 SFT,模型像一个会接龙的人;有了 SFT,它才开始像一个能接指令的人。
RLHF:把回答调得更合人类偏好
RLHF 是 Reinforcement Learning from Human Feedback,基于人类反馈的强化学习。
OpenAI 在 ChatGPT 发布说明里写过,它使用了和 InstructGPT 类似的方法:先让模型生成多个回答,再让人类标注员排序,哪个更好、哪个更差。然后用这些排序训练奖励模型,再用 PPO(Proximal Policy Optimization,近端策略优化)之类的方法继续调模型。
这一步主要调整回答偏好,而不是继续往模型里塞知识。
比如:
- 遇到危险请求,要拒绝
- 不确定时,要承认不知道
- 回答要自然,不要像乱续写
- 用户问错了前提,可以指出来
这三步可以先这样理解:预训练让模型有能力,SFT 让它学会问答格式,RLHF 再把回答调向人类更偏好的样子。
但这里也要说清楚:别把功劳全塞给 RLHF。
RLHF 不等于直接给模型装上“推理能力”。它更像是在调回答风格和偏好。模型能不能推理,跟预训练数据、模型规模、架构、训练方法、后训练数据都有关系。
05|Transformer 架构
LLM 为什么大多跑在 Transformer 上?
先不用急着记技术细节。你可以把它理解成一种更适合“看上下文”的模型结构。
旧方法更像一个人从左到右读句子:读到后面时,前面的信息已经有点模糊了,而且处理速度也容易被“一个词接一个词”的顺序拖住。
Transformer 的关键变化是:处理当前词时,它可以同时看整段上下文,判断哪些词更相关。
比如这句话:
我刚买了一本小说,今天就开始读它。
模型处理“它”时,不能只看“它”这个字。它要回头看前文,判断“它”更可能指向谁。
“小说”的权重应该高,“我”的权重低一点,“今天”的权重也低一点。
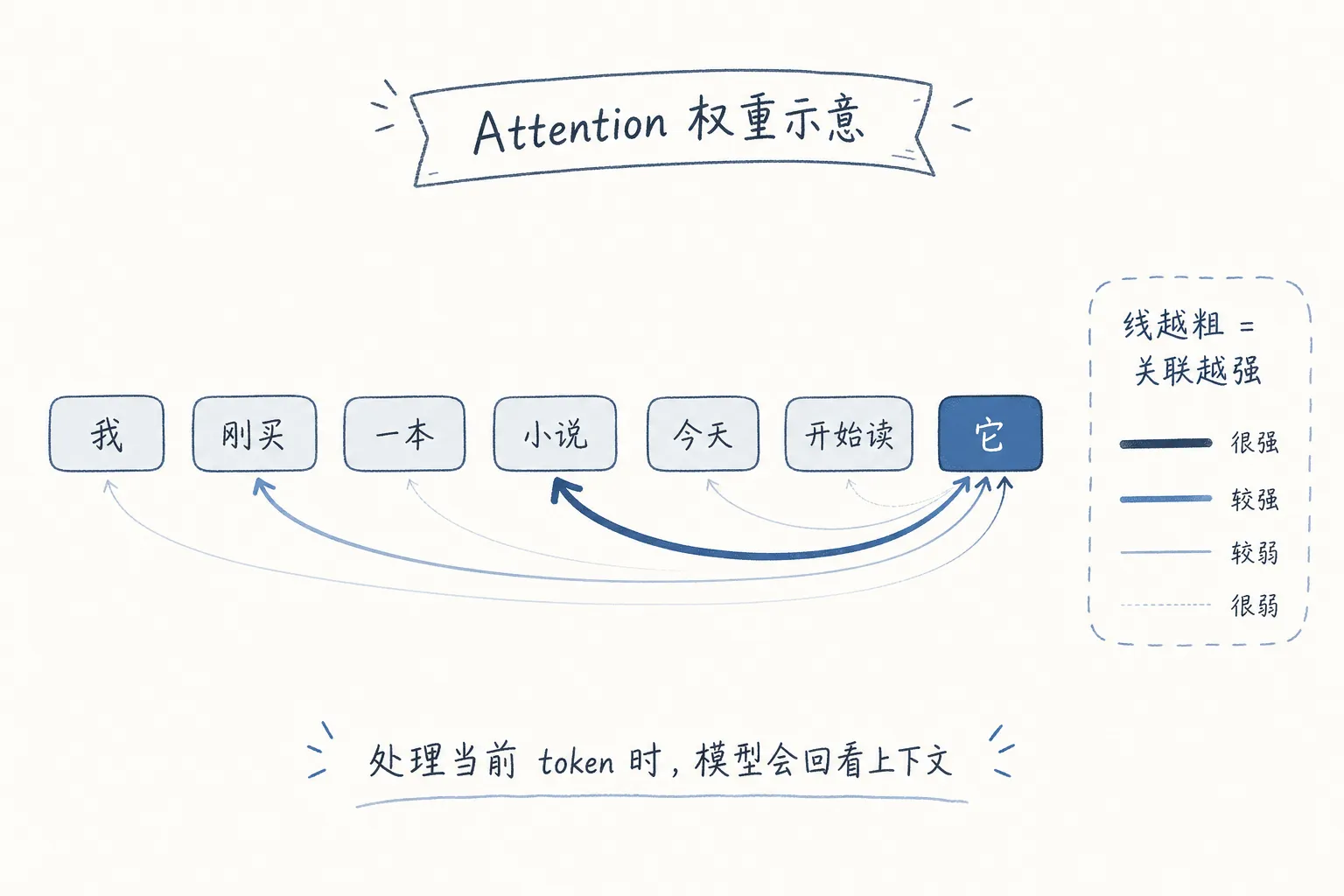
这就是 attention(注意力机制)最直观的作用:让模型知道当前词应该重点参考哪些上下文。
Transformer 后来成为主流,不是因为名字高级,而是因为它更适合处理大段文本,也更适合大规模训练。
进阶细节可以以后再看:RNN、LSTM、并行训练、多头注意力、位置编码,都属于下一层内容。入门阶段先记住一句话就够了:Transformer 让模型能更好地看上下文。
06|Prompt 输入
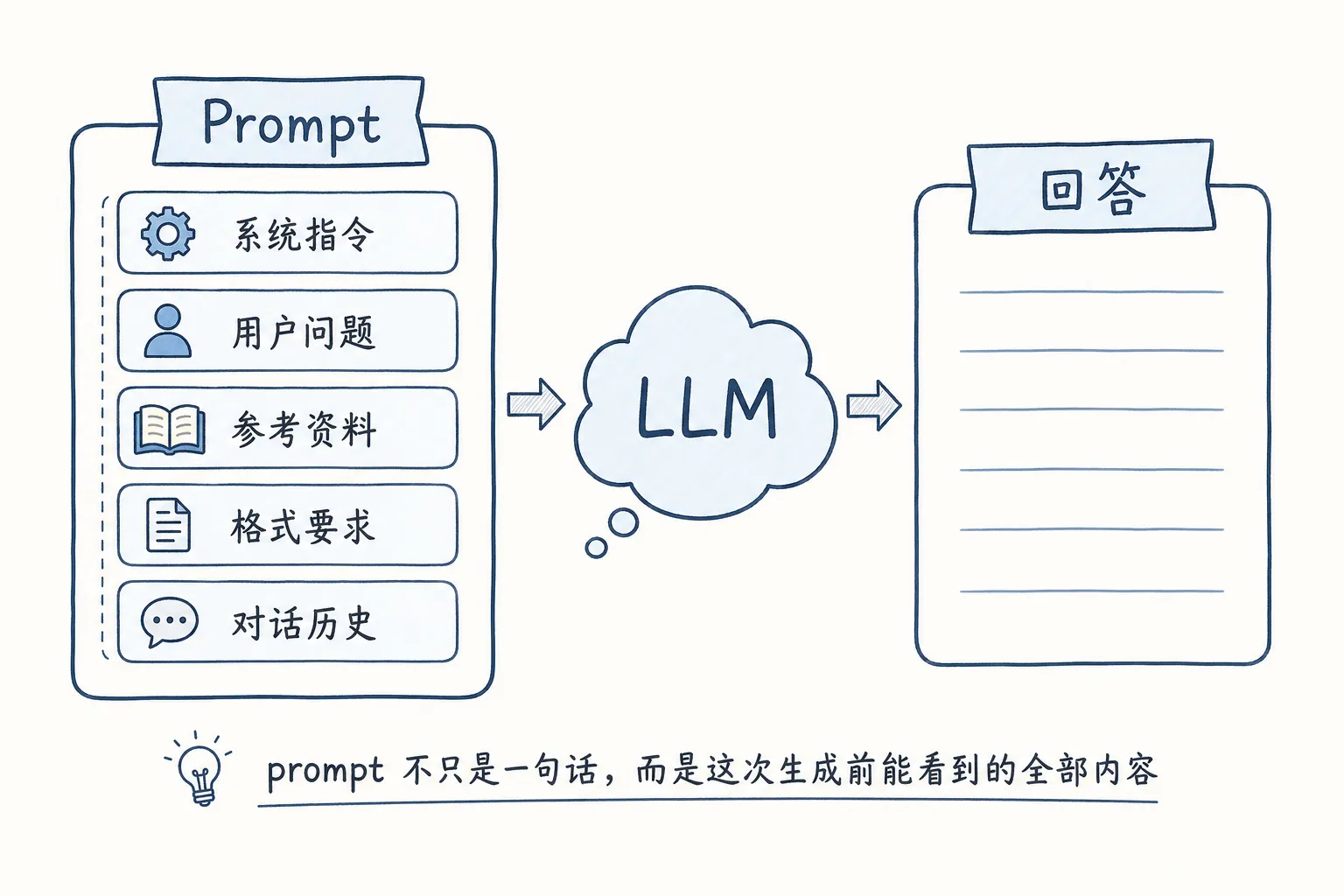
prompt 经常被翻译成“提示词”,但这个翻译有点窄。
它不只是你输入框里的那一句问题。
对模型来说,prompt 是它这次生成前能看到的全部上下文。里面可能包括:
- 你的问题
- 你贴进去的资料
- 你要求的格式
- 你给的例子
- 系统指令
- 对话历史
模型不是凭空回答。它是在当前 prompt 里继续生成。
prompt 写法会直接影响结果。
同样问“帮我总结这篇文章”,你只丢一句话,和你明确告诉它“按三点总结,每点不超过 80 字,保留关键数字,不要加入原文没有的信息”,结果会完全不一样。
这不是玄学。
它只是因为你给模型的上下文不同,模型下一步预测的方向也不同。
System Prompt 也是这个逻辑。它通常放在更靠前的位置,用来告诉模型身份、语气、约束。
差一点的写法通常很泛:
你是一个友好的助手。
这句话不是完全没用,但它给的信息太少。模型只能往“礼貌、温和、尽量回答”这个大方向靠。
更有用的写法会把任务边界说清楚:
你是我的语法搭档。用户每写一段话,你先给出这段草稿最严重的问题——只讲一个。不要鼓励,不要铺垫。直接说问题。
这时候模型不只是知道“我要友好”,而是知道自己该扮演什么角色、每次输出先做什么、哪些话不要说。
模型不会“相信”这些句子,它只是把这些句子也当成上下文的一部分。接下来生成时,会更倾向于符合这段上下文。
prompt engineering 本质上就是上下文组织能力。
07|上下文窗口
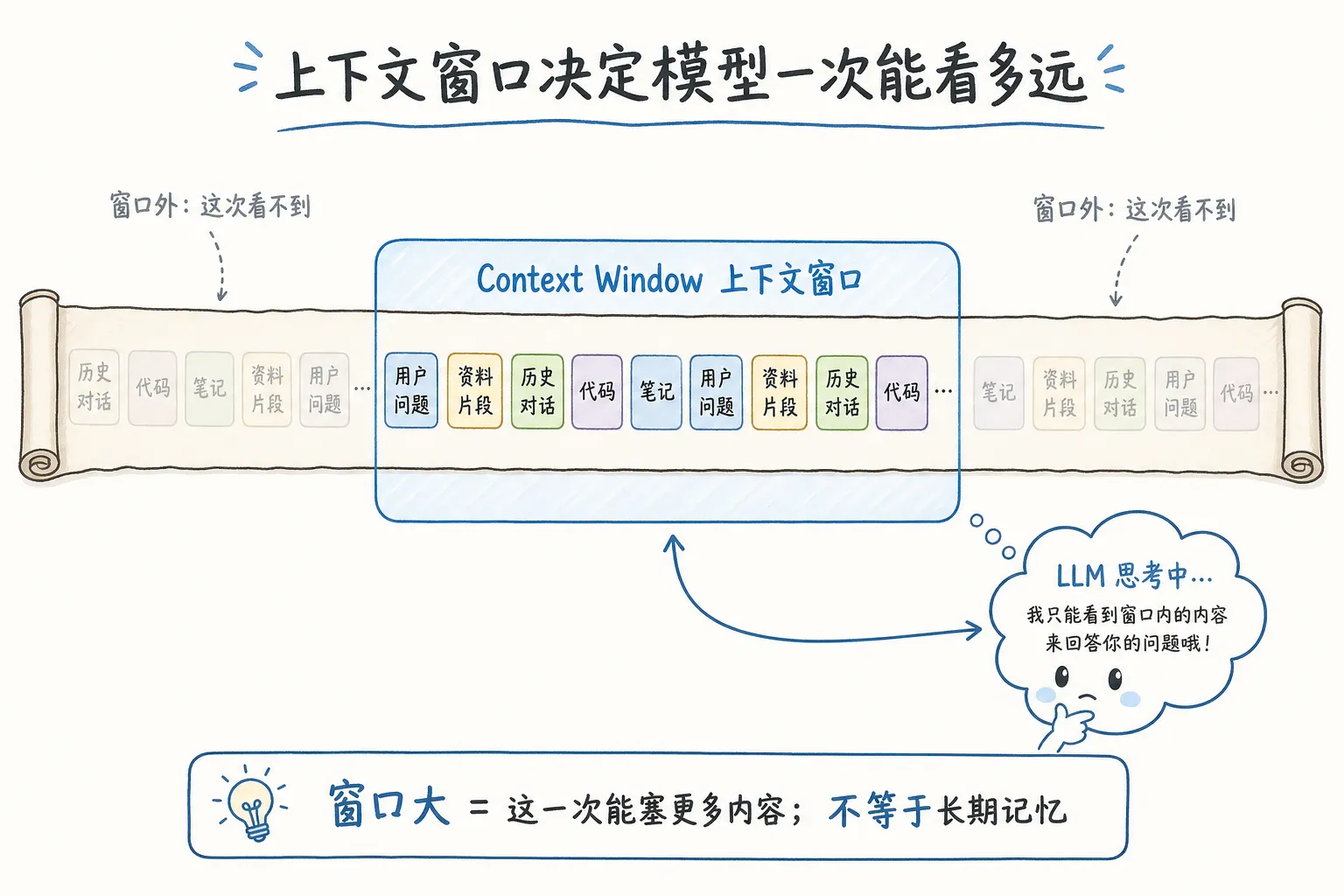
context window,中文常说上下文窗口。
它指的是模型一次能看到的 token 上限。
这个数字在几年里涨得很快:
- 2020 年 GPT-3 约 2K tokens
- 2023 年 GPT-4 有 8K / 32K 版本
- 2023 年 Claude 扩到 100K tokens,Anthropic 说大约对应 75,000 words
- 2024 年 Gemini 1.5 Pro 把窗口拉到 1M tokens
窗口越大,你一次能塞给模型的材料越多。短窗口只能放一个问题和几段上下文;长窗口可以塞论文、代码仓库、会议纪要,甚至一本书的一大部分。
但窗口不是长期记忆。
模型没有因为你昨天聊过某件事,就天然记住你。它能“记得”,通常是因为那段历史还在当前上下文里,或者产品额外做了记忆系统,把你的偏好重新塞回 prompt。
更准确的说法是:
模型不是记住了你,它只是这次还能看见你前面说过的话。
长窗口也不是免费午餐。
你塞进去的内容越多,模型要处理的东西就越多,成本和响应时间都会上去。现实系统会做很多优化,但“大窗口”本身从来不是免费的。
大窗口只能说明这一次能塞进去的内容更多,不代表模型天然拥有长期记忆。
08|采样参数
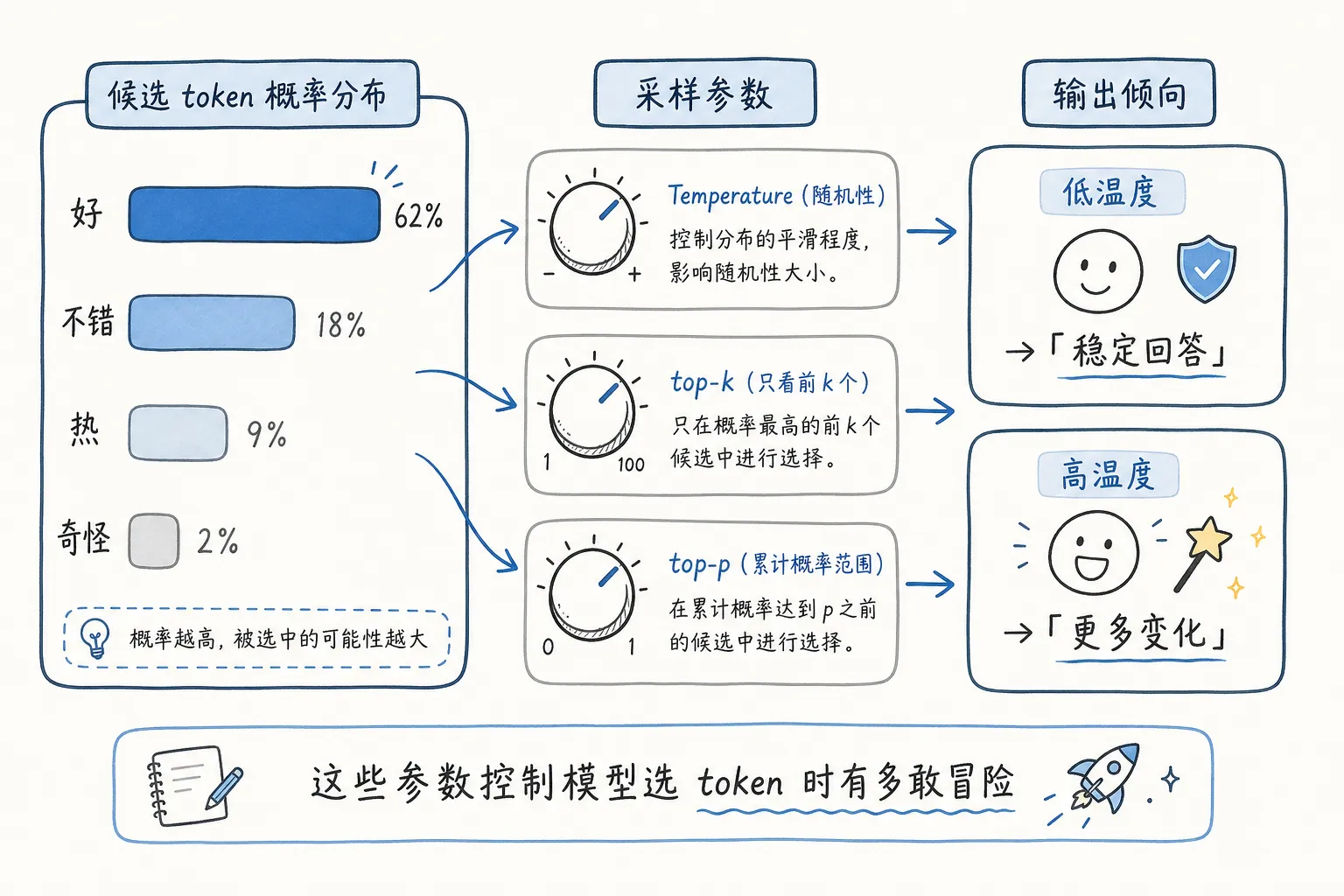
模型每一步都会得到一堆候选 token 和概率。
那它到底选哪个?
这就涉及 temperature、top-p、top-k 这些采样参数。
temperature 管的是随机性。温度低,模型更倾向于选概率最高的 token,输出更稳定,适合事实问答、代码、格式化任务。温度高,低概率 token 也有机会被选中,输出会更发散,更适合头脑风暴、写作、起标题。
如果 temperature 接近 0,同一个 prompt 的结果通常更接近。不是绝对一样,但会稳定很多。
比如同样问一句:
今天晚上吃什么?
低 temperature 更可能给你一个稳妥答案:
可以吃清淡一点,比如鸡胸肉沙拉、番茄鸡蛋面,或者一份简单的日式定食。
高 temperature 更可能往发散方向走:
不如做一个“冰箱盲盒晚餐”:把剩下的鸡蛋、青菜和米饭炒在一起,再配一杯冰美式,假装自己很会生活。
它们不是谁更正确,而是用途不同。写代码、做事实问答时,通常要稳;起标题、找灵感时,可以让它冒一点险。
top-k 和 top-p 也是在收窄候选范围。top-k=40,意思是模型只在概率最高的 40 个 token 里选;top-p=0.9,则是选出一批累计概率达到 90% 的候选 token,再从里面采样。
这几个参数都在调一件事:模型选下一个 token 时,到底有多敢冒险。
写代码时你通常不想它太冒险。写广告语或文章标题时,适当冒险反而可能更有用。
09|幻觉问题
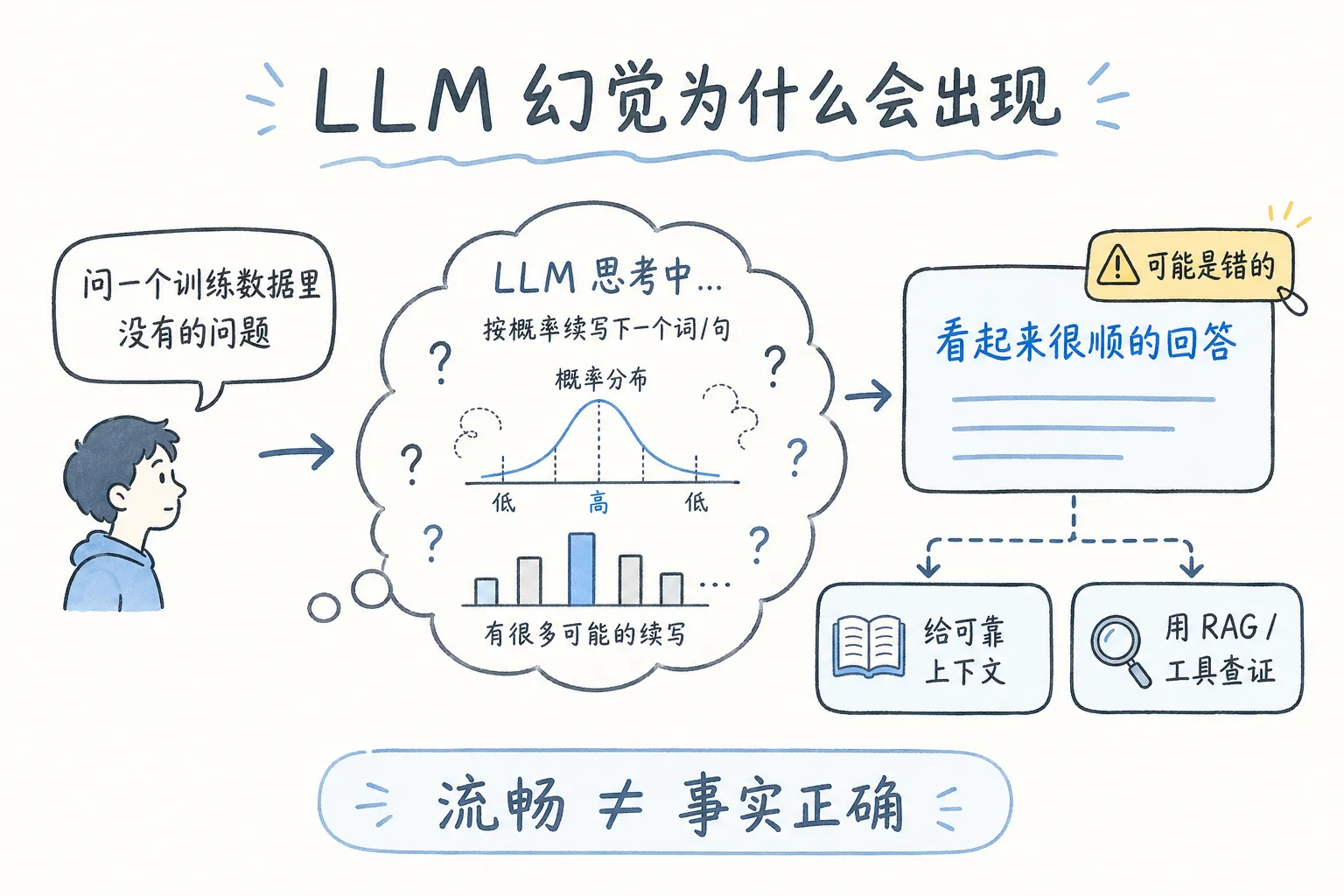
幻觉是 LLM 绕不开的问题。
它指的是:模型输出看起来很顺,语气也很确定,但事实是错的。
OpenAI 在 ChatGPT 发布说明里也提到过,ChatGPT 有时会写出 plausible-sounding but incorrect or nonsensical answers。翻成人话就是:它会给出看起来合理、但其实错误或者没意义的答案。
为什么会这样?
因为模型的基础动作是生成高概率文本,不是查数据库。
你问它一个训练数据里没有、当前上下文里也没有的信息,它不会天然停下来查证。它可能会根据见过的相似模式,生成一个“看起来像答案”的句子。
比如你问一个不存在的论文标题,它可能编出作者、年份、摘要,格式还挺像真的。
它不是偶尔马虎,而是这类生成式模型天生就容易踩的坑。
缓解幻觉的办法很多,但没有一个能把它完全抹掉:
- 给模型可靠上下文
- 让模型引用来源
- 让模型不确定时说不知道
- 用 RAG 接外部知识库
- 用工具调用查实时数据
- 人自己做事实核对
用 LLM 做事实性任务时,态度要硬一点:它可以帮你起草、压缩、改写、找线索,但事实不能只靠它一句话。
10|RAG 检索
RAG 的全称是 Retrieval-Augmented Generation,中文通常叫检索增强生成。
它解决的是一个很实际的问题:模型参数里不可能装下所有最新、最准确、最私有的信息。
公司内部文档、最新政策、你自己的笔记、刚发布的论文,模型可能没见过。就算见过,也不一定记得准。
RAG 的思路是:别指望模型全靠脑子回答,先帮它把材料找出来。
流程一般是:
- 把文档拆成小段
- 转成模型能快速搜索的格式,存起来
- 用户提问时,先找出相关片段
- 把这些片段和问题一起交给模型,让它基于材料回答
这不是重新训练模型。
它更像是考试时允许开卷:模型本身还是那个模型,但这次答题前,你把相关资料塞到了它眼前。
RAG 的好处是能补外部知识,也能让回答更容易追溯来源。Lewis 等人在 2020 年的 RAG 论文里就强调过,把参数记忆和非参数记忆结合,可以让生成更具体、更事实化。
但 RAG 也不是保险箱。
检索错了,模型会基于错材料回答;材料片段不完整,模型会补空;prompt 写得不好,模型也可能忽略关键证据。
RAG 能把模型拉回资料上,幻觉会少一些,但不能指望它把错误彻底清零。
11|工具调用
RAG 解决的是“知道什么”。
工具调用解决的是“能做什么”。
模型本身不会真的查天气、发邮件、跑 SQL(Structured Query Language,结构化查询语言)、执行 Python。它只是生成文本。所谓工具调用,是让模型在合适的时候输出一个结构化请求,然后由外部程序去执行。
OpenAI 在 2023 年的 function calling 更新里给过类似例子:用户问天气,模型不直接编天气,而是生成一个函数调用请求:
get_current_weather(location="Boston", unit="celsius")
外部系统拿到这个请求,去调用天气 API,把结果传回模型。模型再把结果组织成自然语言回答。
有了这一步,LLM 才能从“只会说话”走到“能调工具”。
常见场景包括:
- 联网搜索
- 查询数据库
- 执行代码
- 读取文件
- 发起日程或邮件草稿
- 调用公司内部 API
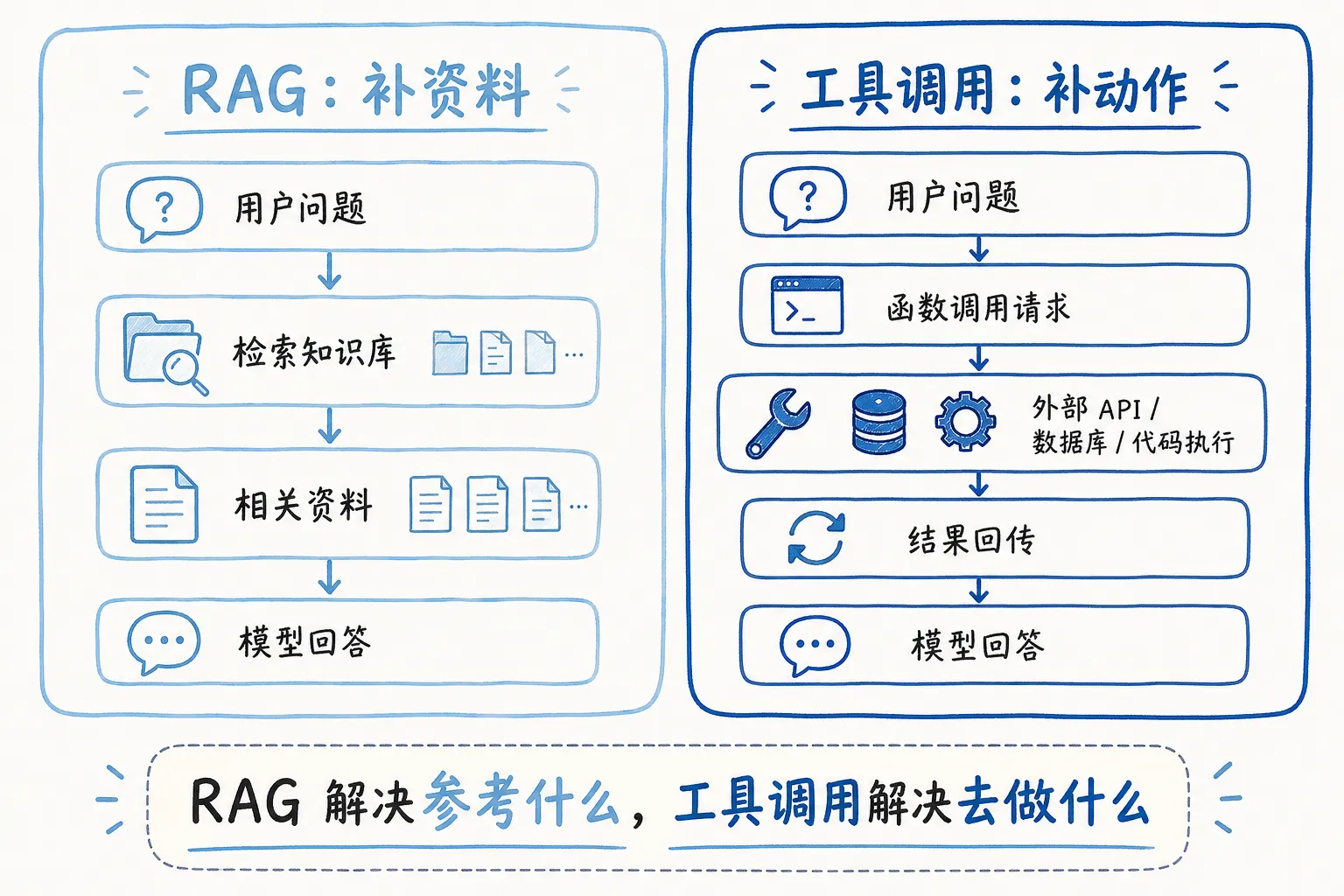
很多看起来很厉害的 AI 应用,底层其实都是 LLM + 工具。
模型负责理解用户意图、生成调用参数、解释结果。真正的实时数据、计算、文件操作、外部动作,交给工具。
这比把 LLM 想成一个万能大脑更准确。
12|模型类型
看模型发布公告时,经常会碰到两组分类:一组在说训练阶段,一组在说模型结构。
先看训练阶段。
base model 更像“会续写的底座”。它在大规模文本上学会了语言模式和知识痕迹,但还不一定会按你的要求回答。GPT-3 最早公开时,更接近这种基础模型的感觉:你给它一个开头,它很会往下续。
instruct model 是在 base model 之后继续调出来的版本。它更会听指令。你让它总结、翻译、改写、列步骤,它更知道自己应该按任务来,而不是随便续写。
chat model 则更偏对话体验。它通常会处理多轮上下文、系统指令、安全边界和回答语气。普通用户平时接触最多的是这一类。ChatGPT、Claude、Gemini 这些产品,背后都是面向聊天体验调过的模型。
再看模型结构。
dense model 可以粗略理解成“每次推理时,大部分参数都一起参与工作”。很多开源模型,比如 Llama 系列,通常会被放在这个框里理解。它的好处是结构直观,部署和推理逻辑相对好理解。
MoE 是 Mixture of Experts,专家混合模型。它不是每次都把所有参数全部激活,而是让不同 token 走向不同“专家”。比如 DeepSeek-V3 的技术报告里写到 671B 总参数、每个 token 激活 37B 参数;Mixtral 8x7B 也属于典型 MoE 路线。你可以先把它理解成:模型总容量很大,但每次只叫一部分专家出来干活,用这种方式控制计算成本。
所以看一个模型名字时,可以拆成两层问:
- 它是 base、instruct,还是 chat?这决定它更像底座、指令模型,还是聊天产品。
- 它是 dense,还是 MoE?这决定它推理时大概怎么花算力。
日常使用 ChatGPT 时,你不需要天天记这些分类。但开始下载本地模型、看技术报告、比较 DeepSeek 和 Llama 时,这些词就会反复出现。
13|理解地图
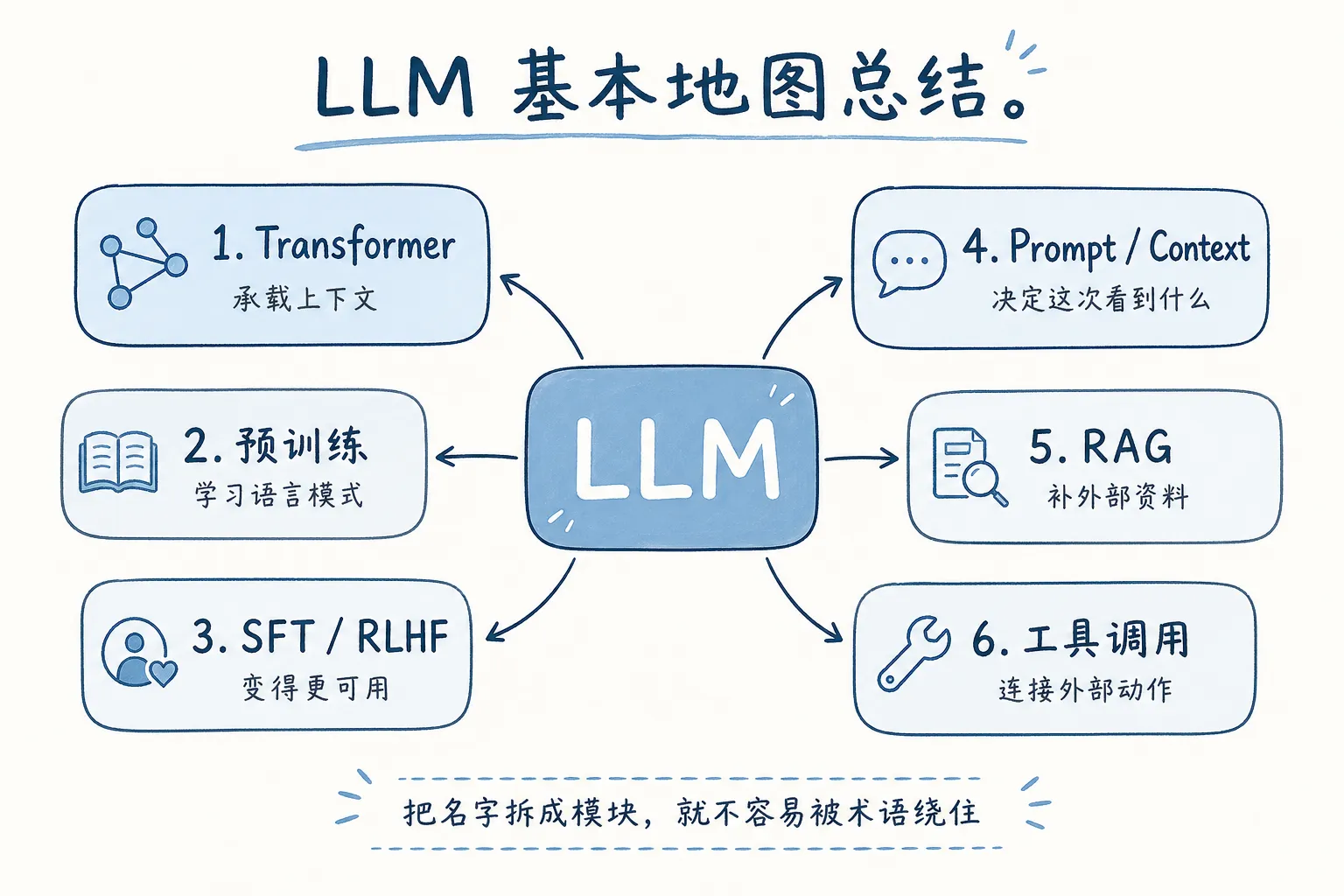
回到开头那段定义。
“大语言模型是基于海量数据预训练的深度学习模型”,这句话没错,但它太像压缩包。真正展开后,里面至少有几层东西:
- token 是它处理语言的单位
- next token prediction 是它生成文字的基础动作
- 预训练让它学到语言模式和大量知识痕迹
- SFT 让它更会按指令回答
- RLHF 让它更贴近人类偏好
- Transformer 让它能带着上下文视野处理序列
- prompt 决定它这次看到什么
- context window 决定它一次能看多远
- temperature 等采样参数影响它回答时有多发散
- 幻觉提醒你它不是数据库
- RAG 给它补外部资料
- 工具调用给它接外部动作
这不是一张词汇表,而是一套拆模型的方法。
LLM 更像一套拼起来的系统。架构和训练决定它的基础能力;后训练让它更适合被人直接使用;prompt、上下文、RAG 和工具调用,则决定它这一次能看到什么、能调用什么。
所以下次看到一个新模型发布,不要只问“它是不是更厉害”。可以换成几组更具体的问题:
- 它是什么架构?dense 还是 MoE?
- 它训练过哪些阶段?只是 base,还是已经 instruct / chat 对齐?
- 上下文窗口多大?长窗口是原生能力,还是产品层做了额外处理?
- 它能不能接工具?实时信息和外部动作从哪里来?
- 它回答事实问题时,证据来自参数记忆、RAG,还是你给它的上下文?
- 它不确定时会怎么处理?承认不知道,还是编一个看起来像答案的句子?
能这样拆,LLM 就不会只剩下一堆名字。ChatGPT、Claude、Gemini、DeepSeek、Llama,看起来都在回答问题,但背后可以沿着同一张地图拆开。
这也是我觉得入门 LLM 最该先建立的直觉:不要先迷信模型名字,先看它这次到底看见了什么、调用了什么、怎么生成下一个 token。