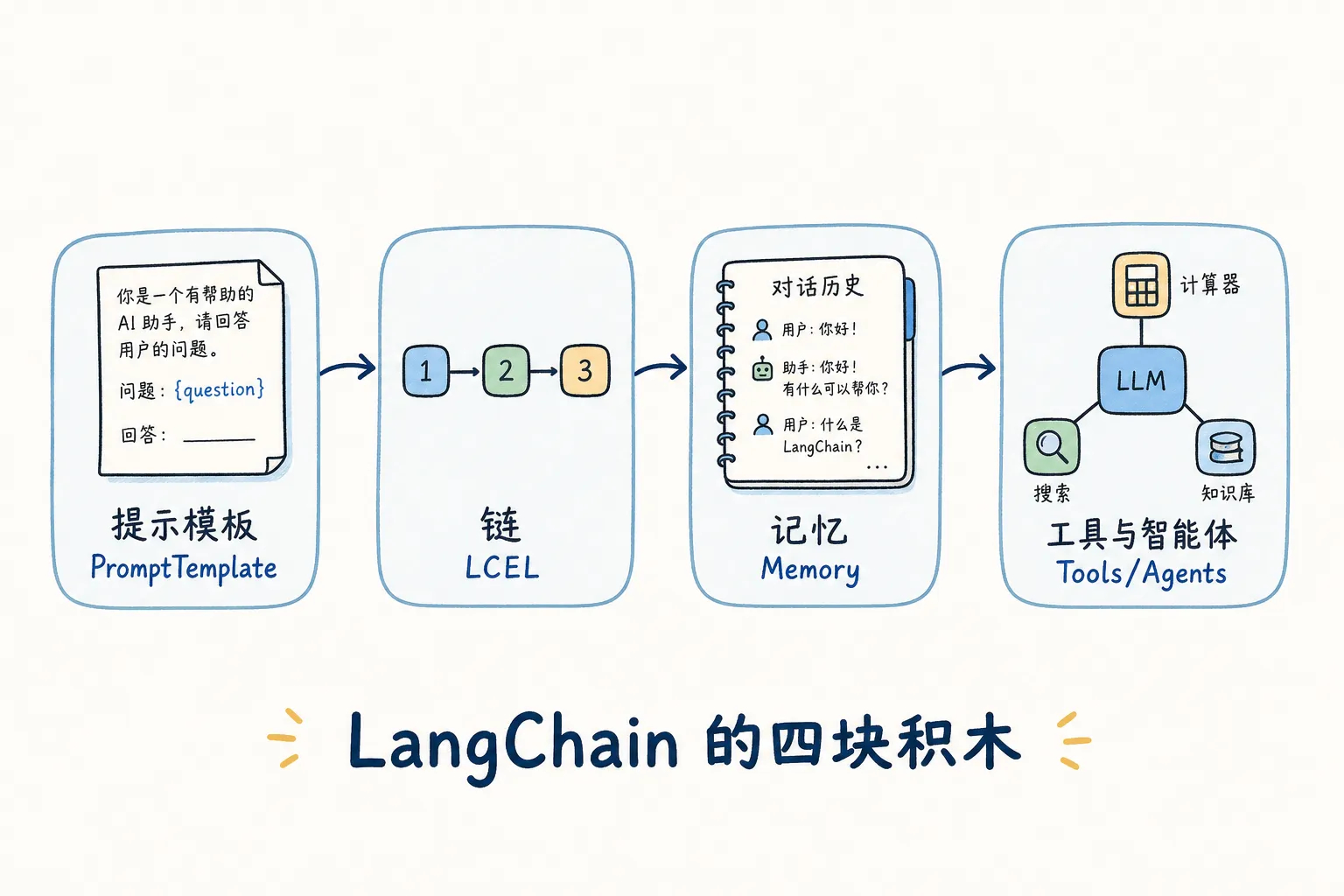
01|从 API 到框架
第 2 篇我们走通了最原始的 LLM 调用链路——一条 prompt 发出去,拿回一个 response。单次调用很简单,三行 Python 搞定。
但现实中的 LLM 应用很少这么单纯。一个小助手要记住上下文、搜索内部文档、算数字、查数据库——需求堆起来的时候,大部分时间不是在写 AI 逻辑,而是在写胶水代码:拼 prompt、存历史、解析工具返回格式、处理错误重试。
这门手艺里有意思的部分是 AI,不是胶水。
LangChain 是 2022 年下半年冒出来的一个 Python 框架,把四件事做成了可复用的积木:
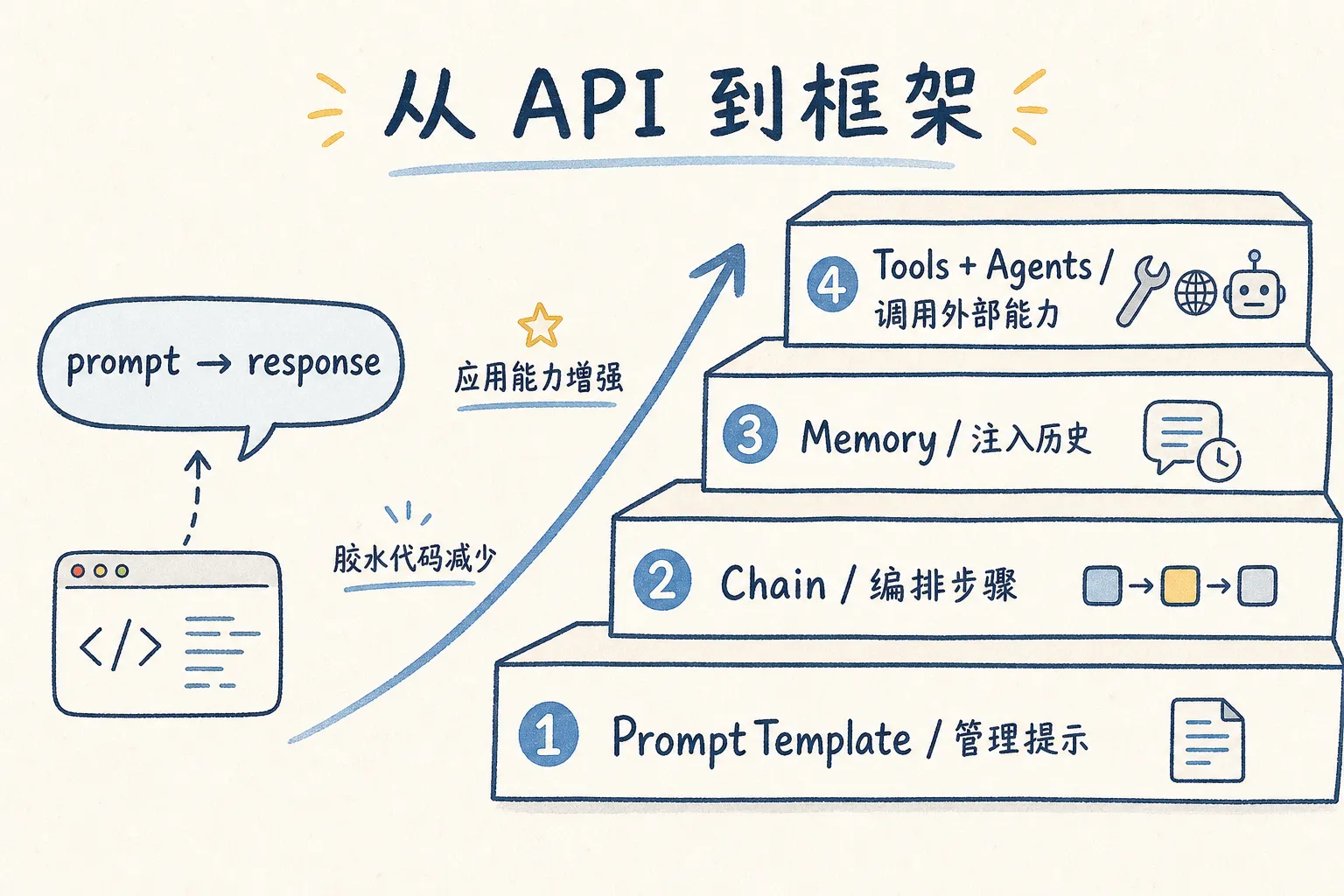
它的 API 版本变动得有点快,不是完美方案。但 GitHub 上快十万星的使用量说明一件事——多数场景里它确实省了很多轮子的重复发明。
02|提示模板
没有模板之前,prompt 是手拼的:
prompt = f"你是{role}专家。用户的问题是:{question}。请用简洁的语言回答。"
字符串拼接。功能上能用,但有两个问题。改 prompt 可能不小心让整个模块崩掉——一个字符串语法错误就行。而且 prompt 和业务逻辑缠在一起,测不了、拆不了,想对比两个版本的效果得手动注释代码。
LangChain 的做法是把它提成独立对象:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是{role}专家。"),
("human", "{question}"),
])
变量变成插槽,prompt 变成声明。改提示文案不动业务逻辑,改变量名不影响提示结构。
当应用需要多种格式的提示时——同一个知识库场景,不同类型的问题配不同的 prompt 模板——组件化的优势更明显:每种模板是一个独立文件,维护成本从「改一大堆 if-else 里的字符串」变成「改一个模板文件」。
LangChain 还提供了 FewShotPromptTemplate,自动把示例格式化塞进 prompt。我第一次觉得这个抽象有用就是在 few-shot 的场景——手拼 few-shot 格式又丑又容易漏,交给模板做干净多了。
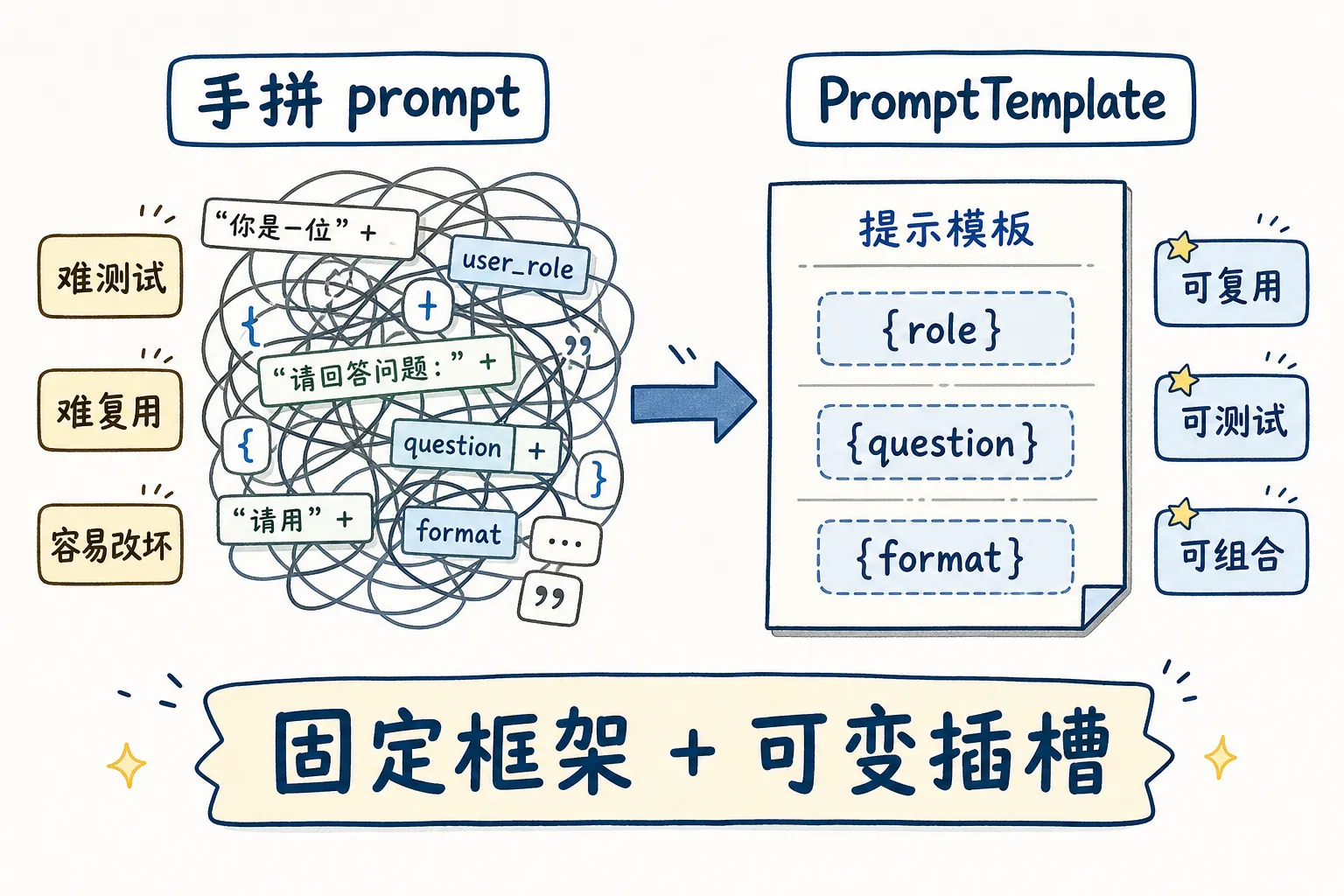
提示模板 = 固定的框架 + 可变的插槽。
03|链
真实应用很少只调一次 LLM。
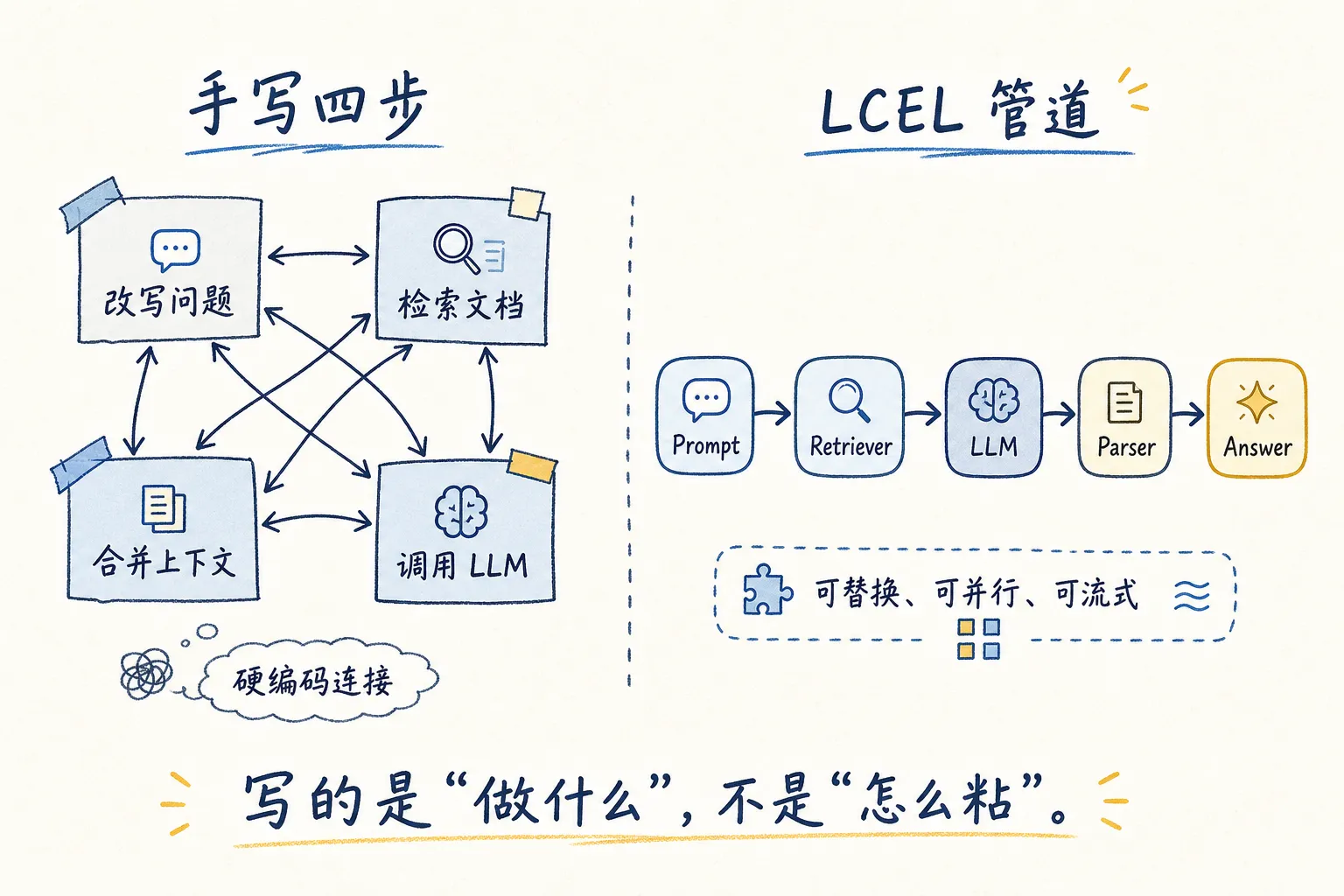
一个常见流程:用户提问题 → 改写为搜索查询 → 检索文档 → 合并文档和问题 → 向 LLM 提问获取答案。四步。
手写的话,四个函数手动传递中间结果:
step1 = rewrite_query(user_input)
docs = search_docs(step1)
context = merge(docs, user_input)
answer = llm_invoke(context)
每个步骤之间是硬编码连接。想抽掉一步、替换一步、加个并行分支,都得重改整个调用链。
LangChain 的「链」就是来管这件事的。最新版的写法叫 LCEL(LangChain Expression Language),用管道符 | 把步骤串起来:
chain = (
ChatPromptTemplate.from_template("基于:{context}\n问题:{question}")
| ChatOpenAI()
| StrOutputParser()
)
chain.invoke({"context": docs, "question": user_input})
管道中的每一步天然支持流式、异步、并行。最关键的区别:写的是「做什么」,不是「怎么做」。箭头符号就是核心关系的直观表达——LLM 调用的输入是 prompt,输出是模型回复,连起来就行,中间的格式转换、变量传递、流式处理,框架处理了。
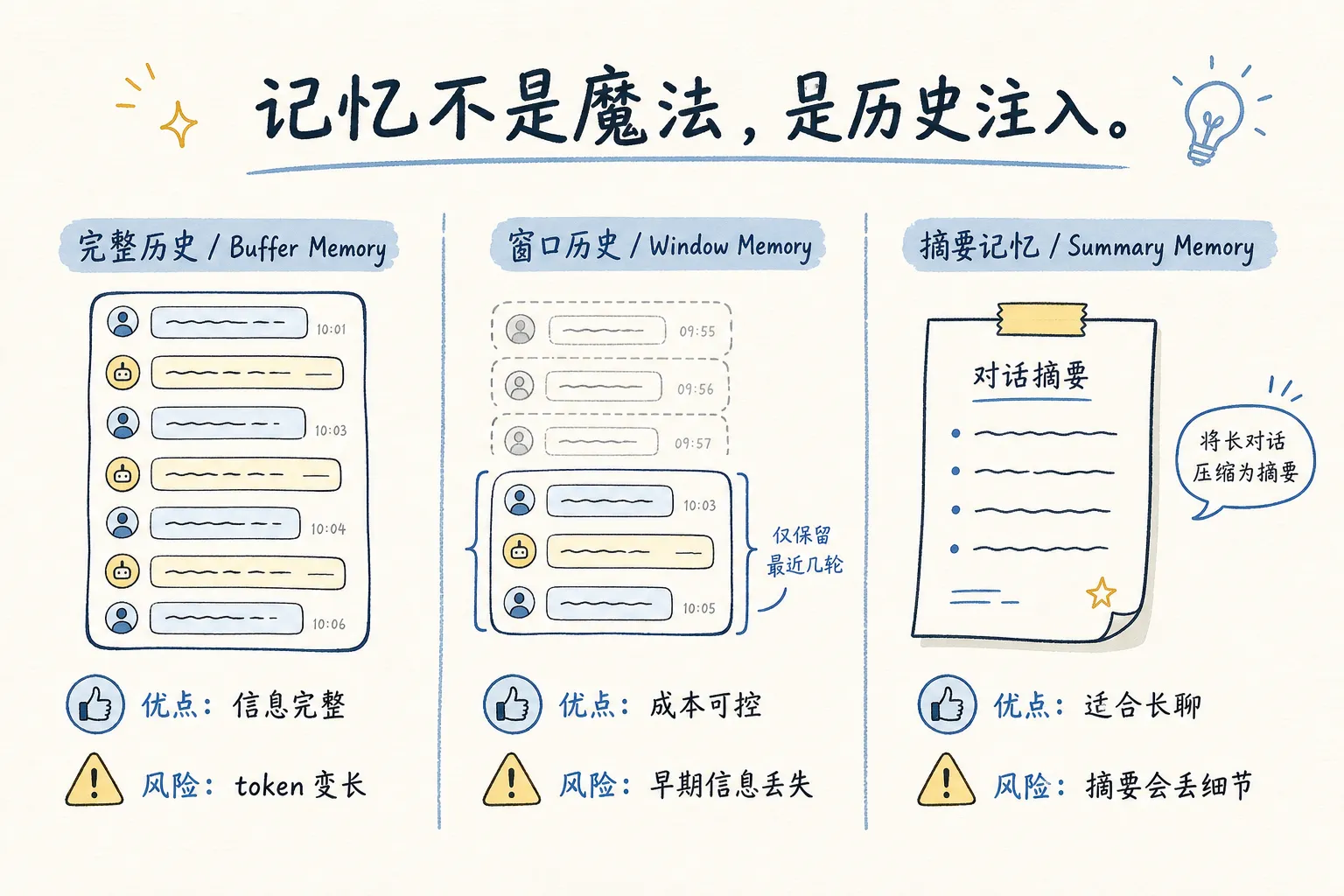
04|记忆
LLM 天生没有短期记忆。每次 API 调用都是独立请求,前一轮说过什么、聊到哪里了,它一概不知道。
手动把历史消息塞进 prompt 的上下文,它才能「想起来」。但每次塞完整历史,prompt 线性膨胀,token 消耗跟着上涨。超过上下文窗口就直接失效。
LangChain 封装了几种记忆策略:
最简单的用法加一行配置就行:
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
memory = ConversationBufferMemory()
chain = ConversationChain(llm=llm, memory=memory)
chain.run("我叫小明。")
chain.run("我叫什么名字?") # → 小明
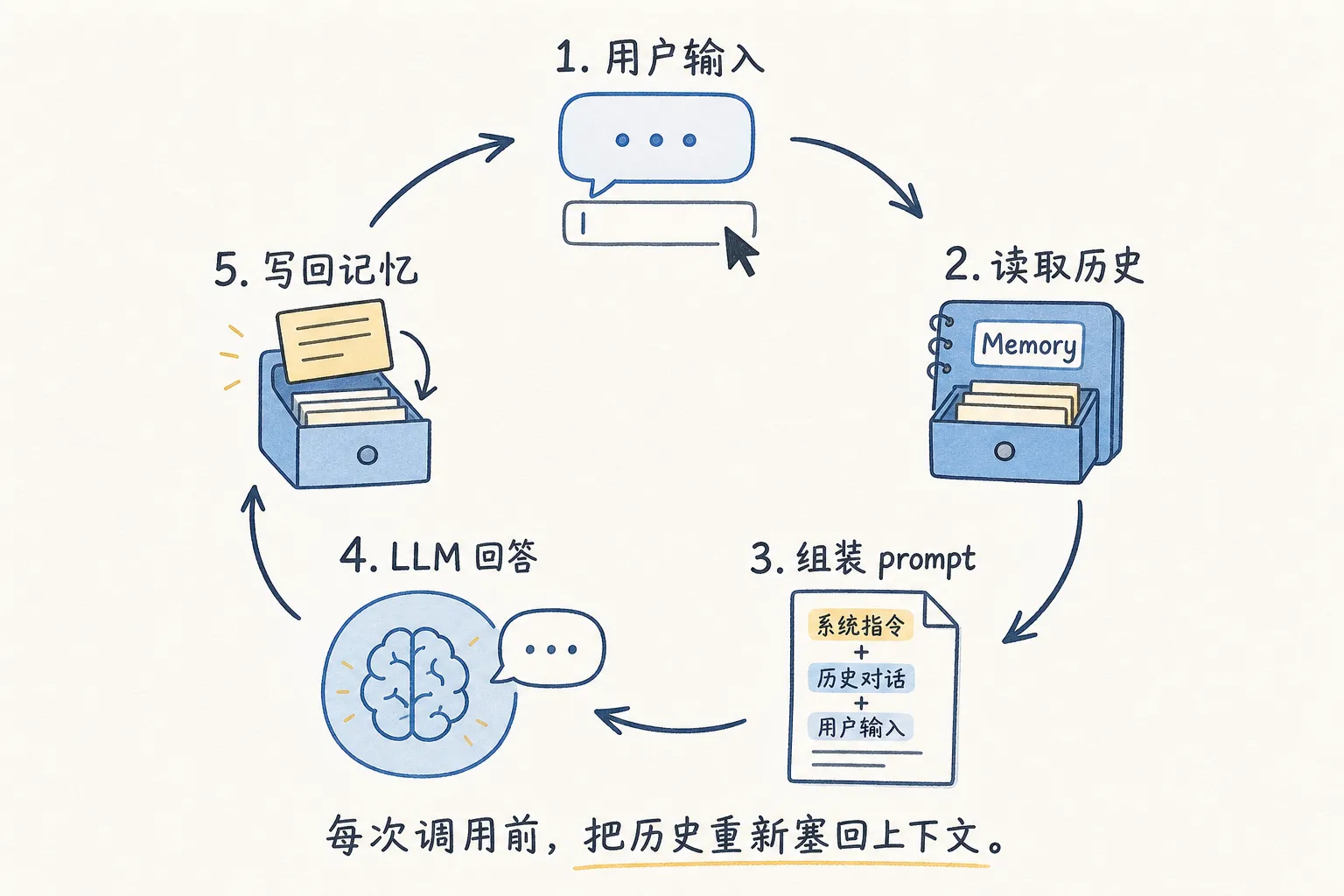
到了生产环境要考虑的东西远多于这行代码:token 预算、摘要质量、多轮后信息丢失。但入门阶段记住**「记忆就是把历史重新注入 prompt」**就够了。
05|工具与代理
前面所有流程都是「人问 → 模型答」的被动模式。
Agent 会自己决定下一步做什么。
它的决策循环叫 ReAct(Reasoning + Acting):
用户问:北京今天天气怎么样?
Agent 思考:我需要查天气 → 我有个 get_weather 工具
Agent 行动:调用 get_weather(city="北京")
工具返回:晴,25°C
Agent 思考:够了,回答问题
Agent 输出:北京今天晴天,25°C
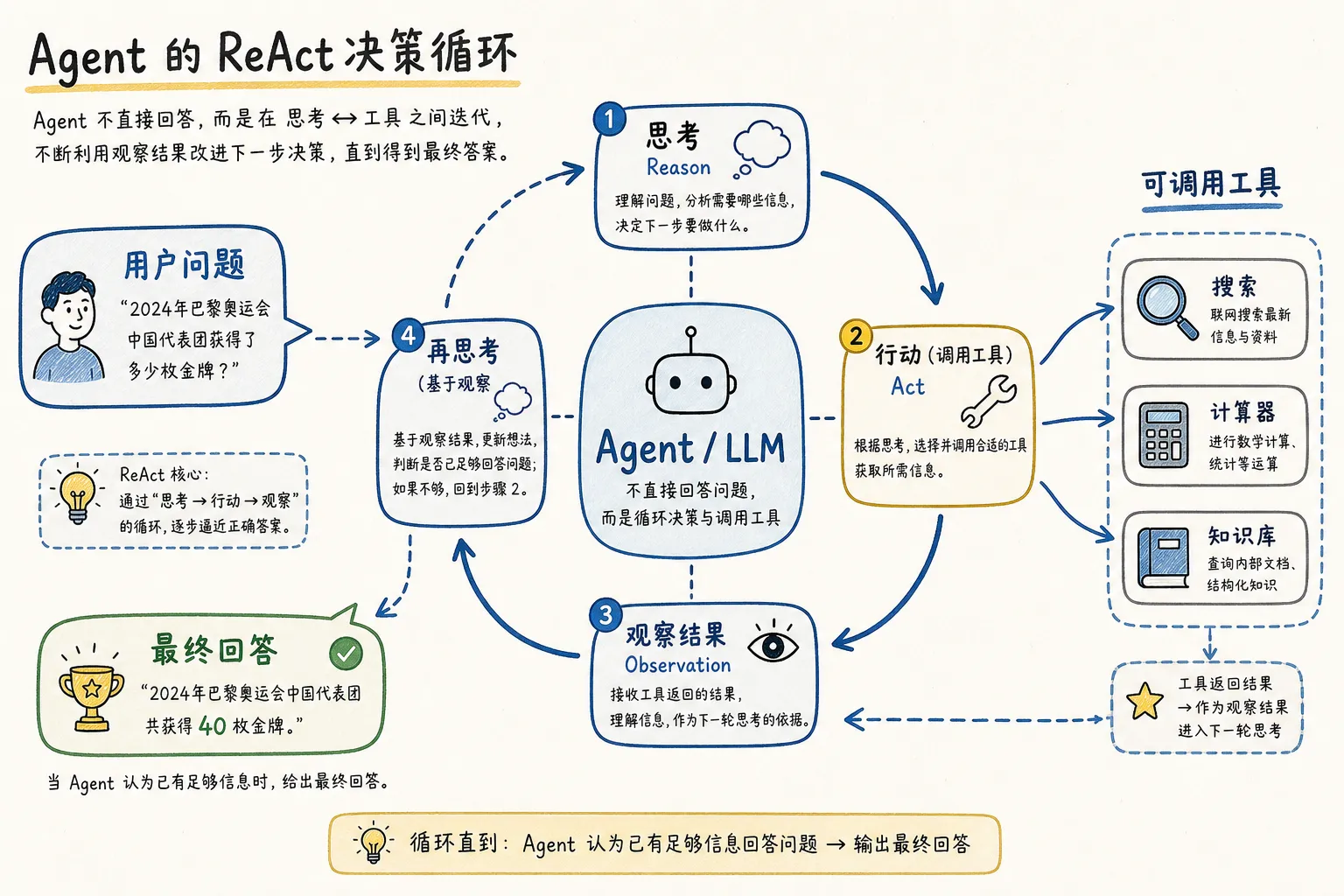
LLM 输出的 Action 格式不可控——参数填错、格式乱、拼写五花八门。LangChain 的 Tool 抽象在这里做的事,是把「人的函数」翻译成「LLM 能理解的语言」:
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
return f"{city}的天气是晴天,25度"
函数上那行注释,就是 Tool 的「身份证」——LLM 读到它就知道这个工具能查天气、参数填城市名。
从单次调用到链式编排,再到 Agent 自主决策,是一条连续的抽象升级线——每一层都在降低一个常见的麻烦。到了 Agent 这层,麻烦已经不在「怎么调 LLM」上,而在「怎么告诉 LLM 它能做什么」。
06|串起来
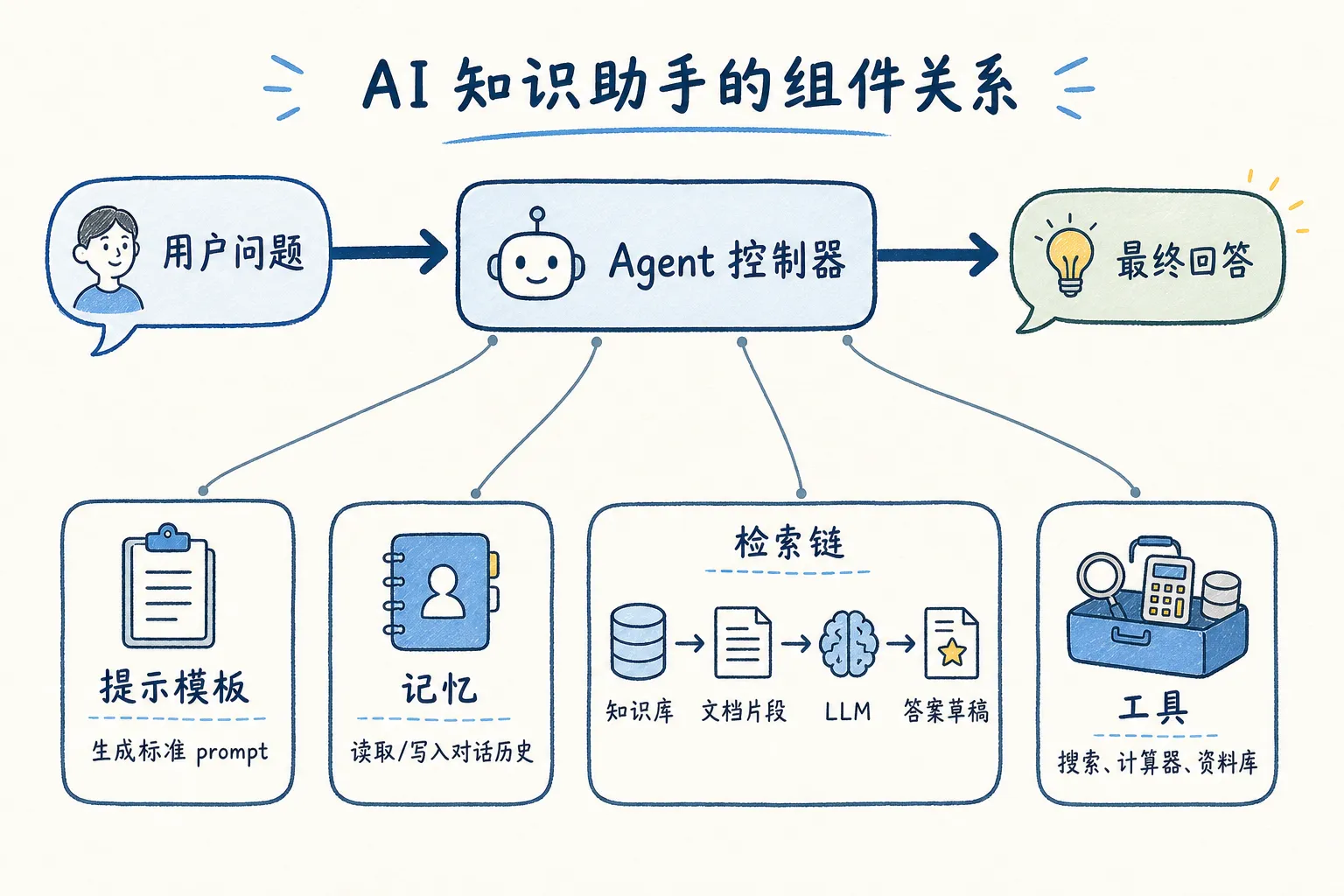
一个「AI 行业知识助手」的完整架子:
# 1. 提示模板
prompt = ChatPromptTemplate.from_template(...)
# 2. 链——编排搜索 + 回答
rag_chain = retriever | prompt | llm | parser
# 3. 记忆
memory = ConversationBufferMemory()
# 4. 工具
tools = [search_knowledge_base, calculator]
# 5. Agent——自主决定用哪个工具
agent_executor = AgentExecutor(
agent=agent, tools=tools, memory=memory
)
每个组件只关心自己的事。提示模板不知道用户问什么,记忆模块不知道答案是什么,Agent 不知道工具怎么实现——它只负责决定用哪个。
把复杂度分摊到独立的积木里,每个积木只做一件事。
回顾 LangChain 解决的四个问题:
- 拼 prompt → 提示模板
- 多步编排 → 链
- 无状态 → 记忆
- 工具接入 → 代理
每个问题的解决,都在逐步把 LLM 从一个黑箱文本生成器变成一个可组合的应用构件。
到 Tool + Agent 这一步,已经接触到今天 AI Agent 的核心雏形。让 LLM 拥有工具使用能力和自主决策能力,在 2022 年 LangChain 刚发布时还是个前沿实验,到了今天,AutoGPT、CrewAI、各种 Agent 框架遍地开花——底层逻辑和 LangChain 的 Agent 本质上是一样的,只不过工程实现更成熟、调度更复杂。
这篇文章里的概念,不只是某个框架的说明书。LangChain 的提示模板、链、记忆、工具这些抽象,就是今天 AI Agent 世界的原始积木。 以后读到各种 Agent 框架的文档,会发现它们都在用同一套语言说话。
LangChain 有多种选择,也有适用边界。一个简单的判断标准:
场景需要 ≥2 个 LangChain 抽象 → 值得用;只要 1 个 → 原生 API 可能更省事。
这是第三篇,也是 LLM 基础概念系列的收尾。从 LLM 的核心原理,到 API 调用链路,再到应用框架的概念框架——已经有了一张可以继续往下走的地图。下一步的 AI Agent、RAG、多模态,都是在这张地图上展开的城市。